FEATURED STORY OF THE WEEK
DGX B300 Core Computing Architecture

Recently, it was announced that Lilly, a global pharmaceutical and life sciences company is deploying the world’s first NVIDIA DGX SuperPOD built on DGX B300 systems, marking the largest and most powerful AI factory operated entirely in-house by any organization. The facility integrates 1,016 NVIDIA Blackwell Ultra GPUs, capable of performing over 9 quintillion calculations per second, demonstrating the scale at which modern AI infrastructure can accelerate complex computation. While this deployment highlights a breakthrough in operational efficiency, the underlying DGX B300 architecture represents a universal foundation for any enterprise aiming to build a high-performance AI platform. In this blog, we take a structured look at the core computing architecture of DGX B300. We will cover the Blackwell Ultra GPU design, the unified HBM3e memory subsystem, the NVLink and networking fabric that enables both scale-up and scale-out performance, and the system’s physical engineering that allows DGX B300 to operate reliably in modern data centers.
Compute Architecture: NVIDIA Blackwell Ultra (B300)
The compute design of DGX B300 reflects a clear response to how modern AI workloads have evolved. Models are larger, reasoning chains are longer, and inference is no longer a lightweight task. Blackwell Ultra (B300) GPUs are built to address these requirements directly, prioritizing sustained throughput, efficient precision formats, and accelerated attention processing. Each DGX B300 system integrates eight NVIDIA Blackwell Ultra GPUs, engineered to function as a tightly coupled compute complex rather than independent accelerators.

Dual-Die GPU Design
Blackwell Ultra introduces a dual-reticle GPU architecture, with each B300 integrating 208 billion transistors across two silicon dies. These dies are connected using NVIDIA High-Bandwidth Interface (NV-HBI), delivering 10 TB/s of on-package bandwidth. From a software perspective, this design is intentionally transparent. The two dies operate as a single logical GPU within the CUDA programming model, allowing applications to scale compute density without introducing additional complexity in scheduling or memory management.
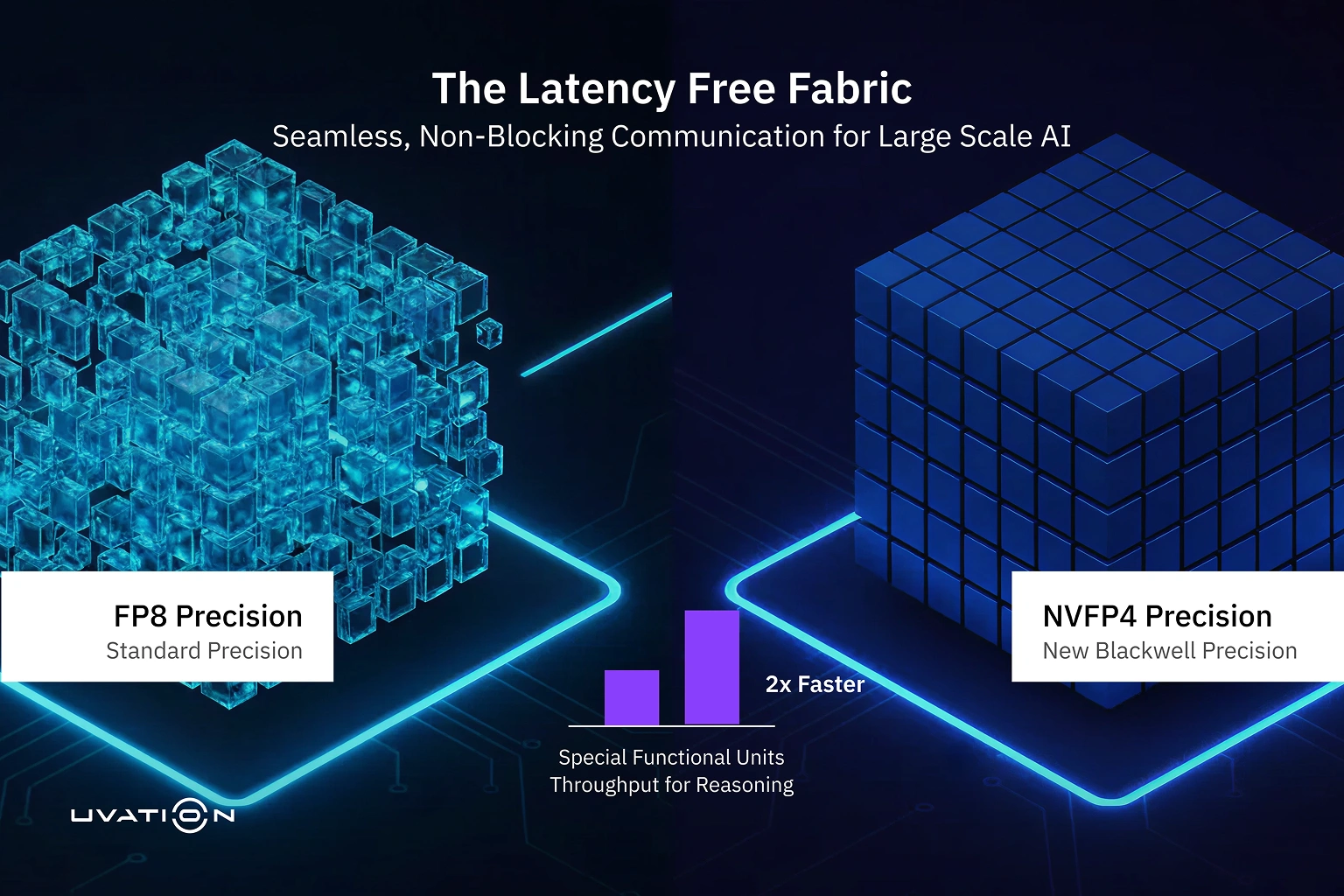
NVFP4 Precision and Compute Throughput
To improve inference efficiency, Blackwell Ultra introduces the NVFP4 precision format. This low-precision format is optimized for transformer-based models and delivers up to 15 petaFLOPS of dense compute per GPU. Compared to FP8, NVFP4 reduces memory usage by approximately 1. 8×, allowing more model parameters and activations to remain resident in GPU memory. For production inference environments, this translates into higher throughput per system while maintaining accuracy levels suitable for large language and reasoning models.
Acceleration for Reasoning and Attention Workloads
Reasoning-centric models place significant pressure on attention layers, particularly when operating with long context windows. To address this, Blackwell Ultra doubles the throughput of Special Function Units (SFUs), which play a critical role in attention computation. This architectural change enables up to 2× faster attention-layer performance compared to the previous generation, reducing latency and improving utilization during inference and training workloads where attention operations dominate execution time.
Memory Architecture: Unified HBM3e at Scale
The performance of large AI models is closely tied to how efficiently they can access memory. DGX B300 addresses this challenge with a combination of high-capacity GPU memory and ultra-high bandwidth, ensuring that compute engines remain fully utilized even for models with hundreds of billions of parameters.
High-Capacity GPU Memory
Each DGX B300 system provides 2. 3 TB of total GPU memory, with 288 GB of HBM3e per GPU. This represents a 3. 6× increase over the H100 generation, supporting models with over 300 billion parameters without relying on system RAM or slower storage tiers. Keeping models fully resident in GPU memory reduces data transfer overheads and ensures that large-scale inference and training workloads maintain consistent performance.
High-Bandwidth Memory Design
Memory bandwidth is critical for maximizing GPU utilization. Each B300 GPU uses 12-high HBM3e stacks, delivering up to 8 TB/s of memory bandwidth. This bandwidth ensures that the compute engines receive data continuously, preventing stalls during high-intensity operations such as training large transformer models or running real-time inference on multi-step reasoning tasks. By combining high capacity and high bandwidth, the DGX B300 memory subsystem enables complex workloads to execute efficiently, making it suitable for both research-scale experiments and production-grade AI pipelines.
Interconnect and Networking Architecture
Efficient data movement is a critical factor in large-scale AI performance. As models grow in size and computational demands increase, the ability of GPUs to communicate with each other and with other systems in a cluster becomes as important as the raw compute power. DGX B300 addresses this challenge through a combination of high-speed intra-system interconnects and robust cluster-level networking.
Intra-System Scale-Up: NVLink 5
Within a single DGX B300 system, the eight Blackwell Ultra GPUs are tightly coupled using fifth-generation NVIDIA NVLink. Each GPU achieves 1. 8 TB/s of bidirectional bandwidth, enabling memory sharing and distributed computation across the entire set of GPUs. This design allows applications to treat the GPUs as a single logical unit, rather than eight separate accelerators. Workloads such as long-context reasoning, large-scale inference, or generative AI benefit directly, as memory access and intermediate computation can be efficiently distributed without creating bottlenecks.
Inter-System Scale-Out Networking
Scaling beyond a single system requires high-performance networking to maintain throughput and low latency. DGX B300 includes:
- Eight OSFP ports, supporting up to 800 Gb/s InfiniBand or Ethernet via NVIDIA ConnectX-8 SuperNICs, ensuring high-speed cluster interconnects.
- Two dual-port NVIDIA BlueField-3 DPUs, providing specialized functions for storage acceleration, infrastructure management, and security isolation.
This combination of intra-system NVLink and inter-system networking ensures that DGX B300 can support distributed training and inference efficiently. Whether deployed in single-system configurations or as part of a multi-node SuperPOD, the architecture is optimized for low-latency, high-throughput communication, which is essential for scaling modern AI workloads.
System Design and Physical Engineering
The DGX B300 is not only a high-performance compute system but also engineered for operational efficiency, reliability, and seamless integration into modern data centers. Every aspect of its physical design, power configuration, and supporting infrastructure has been optimized to complement the capabilities of Blackwell Ultra GPUs.
Chassis and Form Factor
The system is housed in a 10 Rack Unit (RU) chassis, a design specifically tailored for ease of serviceability and data center deployment.
- Front-Accessible I/O: All input/output interfaces are positioned at the front, simplifying cabling, maintenance, and upgrades without requiring access to the rear.
- Rear Thermal Access: Cooling fans are located at the rear of the chassis, allowing efficient thermal servicing and airflow management without system downtime.
- Data Center Integration: The compact 10 RU form factor maximizes compute density while ensuring compatibility with standard rack configurations.
Power and Infrastructure Compatibility
DGX B300 is designed for flexible deployment across a variety of power infrastructures:
- Power Consumption: Approximately 14. 5 kW per system under full load.
- Power Options: Available in both AC/PDU and DC/busbar configurations, ensuring compatibility with diverse data center architectures.
This versatility allows organizations to deploy DGX B300 in both greenfield and existing facilities without extensive modifications, supporting high-performance operations while maintaining energy efficiency.
CPU and System Memory
While the GPUs deliver the bulk of compute power, DGX B300 also includes a robust supporting platform:
- Processors: Two Intel Xeon Platinum 6776P CPUs provide sufficient computational capacity for orchestration, preprocessing, and auxiliary workloads.
- System Memory: Standard 2 TB of DDR5 memory, expandable up to 4 TB, enables smooth integration with GPU workloads and large-scale data processing tasks.
This combination ensures that the system can handle end-to-end AI pipelines, from data ingestion and preprocessing to multi-GPU training and real-time inference, without introducing bottlenecks outside the GPU compute layer.
Final Word
The DGX B300 system represents a major advancement in AI infrastructure, combining powerful Blackwell Ultra GPUs, high-capacity HBM3e memory, and high-speed NVLink interconnects to handle complex reasoning and generative workloads efficiently. Fully leveraging its capabilities requires careful planning, including integration with data center power, cooling, and networking, as well as alignment with specific AI workloads. With proper preparation, organizations can translate this advanced hardware into sustained performance and scalability, leading naturally into solutions such as Semifly Marketplace for deployment guidance and support.
DGX B300 Deployment Guidance via Semifly Marketplace
Deploying a system as advanced as DGX B300 requires careful planning, infrastructure alignment, and workload-specific configuration. Organizations need to ensure that power, cooling, networking, and system orchestration are all optimized to fully leverage the compute, memory, and interconnect capabilities described earlier. Without proper planning, even the most powerful system can face underutilization or operational inefficiencies. Semifly Marketplace provides a centralized platform for organizations to navigate the complexities of DGX B300 adoption. Through the marketplace, teams can:
- Explore system configurations aligned with specific AI workloads
- Assess data center readiness, including power and cooling requirements
- Plan integration with existing networking and storage infrastructure
- Access advisory support for optimizing performance and efficiency
Organizations looking for personalized guidance can also schedule a free consultation with Semifly experts to understand deployment requirements, optimize infrastructure, and align their DGX B300 strategy with long-term AI goals.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now