FEATURED STORY OF THE WEEK
Unlocking the Power of NVIDIA Networking Software Tools for AI and HPC

Networking has become a critical foundation for modern AI, high-performance computing, and cloud data centers. Training large language models, running simulations, or supporting real-time applications requires thousands of GPUs and CPUs working together. To make this possible, the infrastructure must move massive amounts of data quickly and reliably.
This is where NVIDIA networking software tools play an important role. These tools ensure low latency (minimal delay in data transfer), high throughput (ability to handle very large data flows), and secure connectivity across servers and clusters. By managing how information flows, they prevent bottlenecks that could slow down AI workloads.
Their impact becomes even more important with next-generation GPUs such as the NVIDIA H200, which delivers high-bandwidth memory (HBM3e) and faster performance than the H100. When paired with optimized networking, the H200 can train larger AI models, scale HPC workloads more efficiently, and deliver better performance for enterprises building data centers of the future.
1. What Are NVIDIA Networking Software Tools?
NVIDIA networking software tools are a set of solutions that power modern data centers by making networks faster, more efficient, and easier to manage. These tools are built to support the rising demand for AI, HPC, and cloud applications, where massive amounts of data need to move between servers in real time. They focus on improving connectivity so that computing resources can work together seamlessly without delays.
In NVIDIA’s ecosystem, these networking tools integrate with GPUs, DPUs (Data Processing Units), and high-speed switches. DPUs such as NVIDIA BlueField handle data movement, offloading tasks like security and storage management from the CPU. This frees up system resources while maintaining fast and secure communication. When paired with GPUs such as the H100 or NVIDIA H200, these software tools ensure that the hardware can achieve its full potential in training and inference tasks.
The key advantage of NVIDIA networking software tools is that they allow organizations to build software-defined data centers. This means administrators can manage and configure the network using software instead of manually handling hardware settings. As a result, data centers become more flexible, scalable, and AI-ready. This approach is essential as enterprises shift toward workloads that require rapid scaling and secure multi-node GPU clusters.
2. How Do NVIDIA Networking Software Tools Improve AI and HPC Workflows?
Efficient networking is critical for both AI and HPC because these workloads often run at very large scales. Training large language models or running scientific simulations involves thousands of GPUs working together. Without fast and reliable communication between GPUs, performance slows down and overall efficiency drops. NVIDIA networking software tools ensure that these systems exchange data at high speed, which keeps training and inference pipelines running smoothly.
High-bandwidth and low-latency interconnects play an important role here. Bandwidth refers to the amount of data that can be transferred per second, while latency is the time it takes for the data to move from one point to another. For LLMs and multimodal AI applications, both are critical. If bandwidth is too low or latency is too high, GPUs spend more time waiting than computing. By optimizing these interconnects, NVIDIA networking software tools allow AI systems to scale without facing communication bottlenecks.
These networking capabilities become even more powerful when combined with the NVIDIA H200 GPU. The H200 already provides massive memory bandwidth and improved efficiency for AI workloads. However, without the right networking layer, much of this performance could be wasted in communication delays. By reducing bottlenecks, NVIDIA networking software tools make sure that the H200’s performance gains translate into faster training, quicker inference, and better utilization of resources.
Table: Key Networking Benefits for AI and HPC
| Benefit | How It Helps AI/HPC | Example with NVIDIA H200 |
|---|---|---|
| High Bandwidth | Faster data transfer between GPUs | Supports large LLM training |
| Low Latency | Reduces wait time in distributed training | Efficient scaling across GPU clusters |
| Scalability | Handles multi-node environments | Useful in exascale computing |
| Reliability | Ensures consistent performance | Stable multi-GPU pipelines |
3. What Are the Core NVIDIA Networking Software Tools?
NVIDIA provides a suite of networking software tools that enable high-performance, secure, and scalable data center environments. These tools are designed to work seamlessly with NVIDIA GPUs, DPUs, and switches, making them essential for AI, HPC, and cloud-native infrastructures. Together, they help operators monitor, automate, and optimize their networking layers, which ensures maximum efficiency. Using NVIDIA networking software tools, organizations can reduce latency, improve reliability, and support demanding AI workloads at scale.
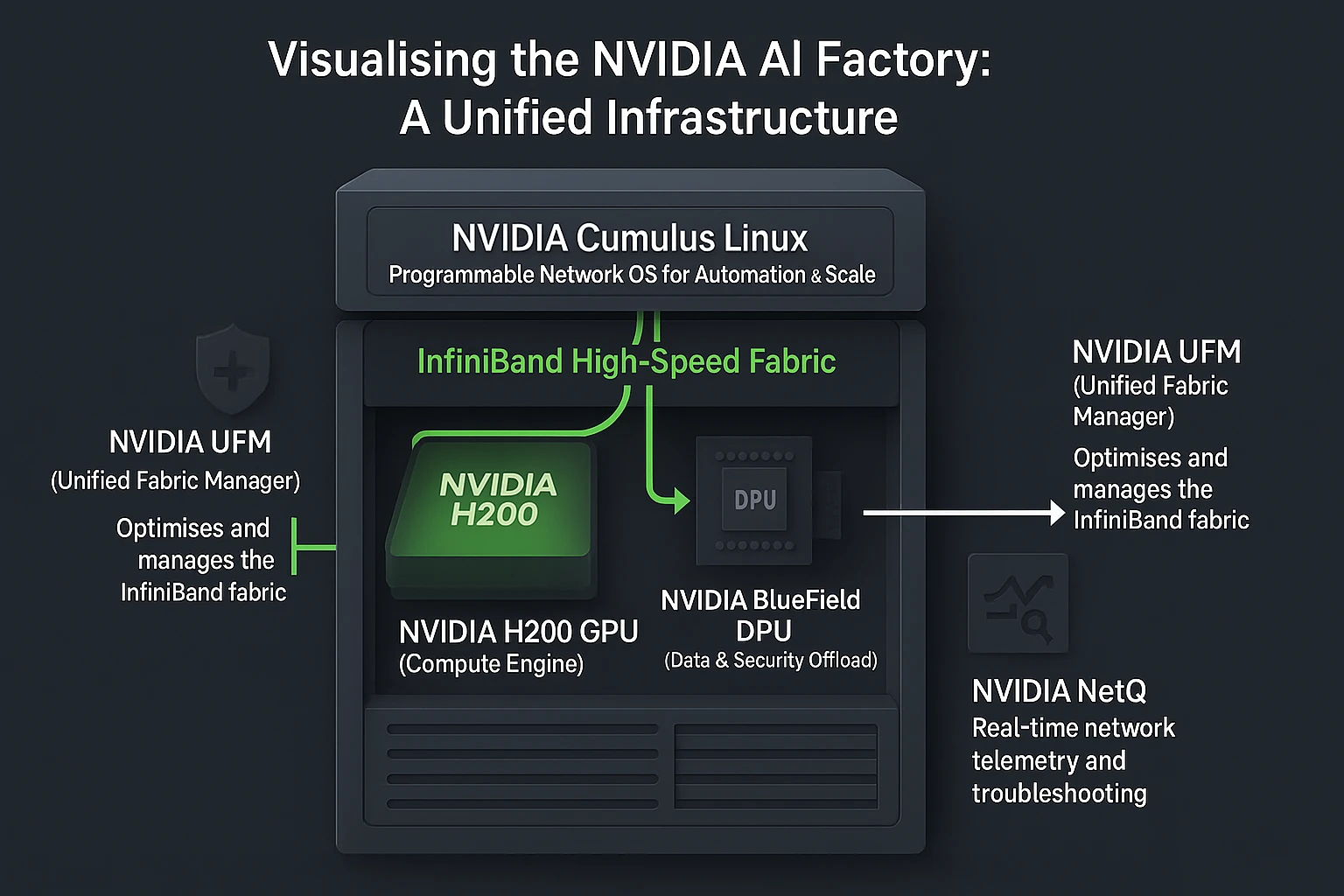
NVIDIA NetQ
NVIDIA NetQ is a real-time telemetry and monitoring solution for large-scale data center networks. It gives visibility into packet movement across the network and helps detect issues such as packet drops, bottlenecks, and latency spikes. By providing detailed insights, NetQ enables faster troubleshooting, which is crucial for AI clusters where delays can significantly slow down workloads. This tool ensures that GPU clusters, including those with NVIDIA H200, stay optimized and consistently deliver high throughput for AI and HPC workflows.
NVIDIA Cumulus Linux
NVIDIA Cumulus Linux is a Linux-based network operating system built for switches. Unlike traditional network OS, it supports programmability, automation, and integration with modern DevOps tools. This allows data center operators to configure and manage their networks in a way similar to managing servers. Cumulus Linux is especially valuable in AI-ready data centers because it enables flexibility, reduces manual effort, and ensures consistent performance. As part of the NVIDIA networking software tools portfolio, it helps create highly scalable and cloud-native environments.
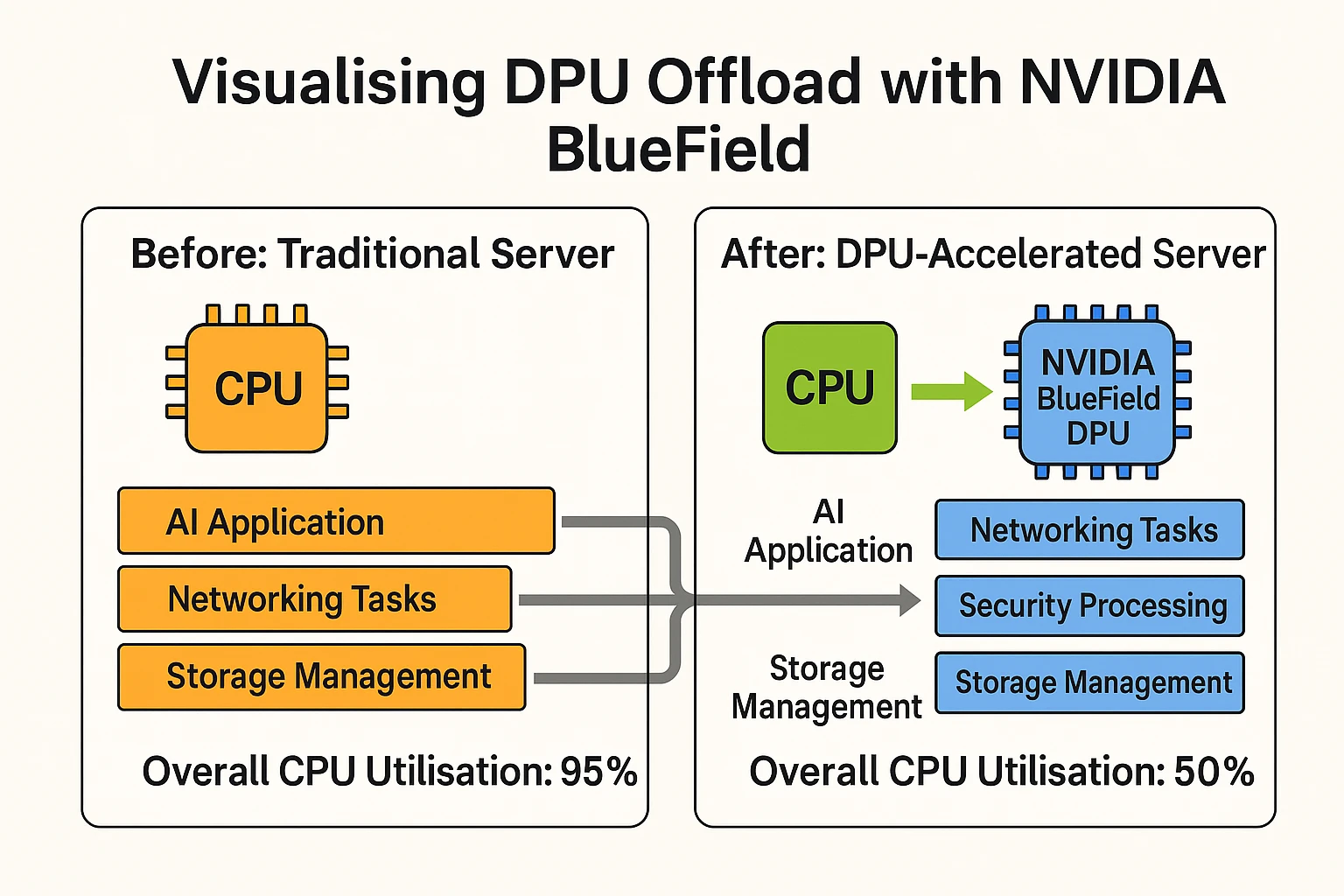
NVIDIA DOCA (Data-Center-on-a-Chip Architecture)
NVIDIA DOCA is a software framework designed to run on BlueField DPUs. A DPU, or Data Processing Unit, is a processor that offloads networking, storage, and security tasks from the CPU, freeing it up for more critical operations. DOCA provides developers with APIs and libraries to build applications that optimize data movement, enhance security, and improve system efficiency. In AI and HPC contexts, DOCA ensures that workloads run faster and more securely by minimizing CPU overhead. This makes it a critical component of NVIDIA networking software tools in modern data centers.
NVIDIA UFM (Unified Fabric Manager)
NVIDIA UFM is a fabric management platform used primarily for InfiniBand networks, which are high-speed interconnects widely deployed in supercomputers and AI clusters. UFM enables administrators to monitor network health, balance workloads, and perform predictive failure analysis. This proactive approach prevents downtime and ensures that resources are used efficiently. For AI training environments powered by the NVIDIA H200, UFM plays a key role in ensuring stable and scalable performance. As one of the advanced NVIDIA networking software tools, it gives operators full control over complex fabrics in large-scale deployments.
Table: Overview of Core NVIDIA Networking Software Tools
| Tool | Primary Function | Key Benefit in AI Environments |
|---|---|---|
| NetQ | Network visibility & troubleshooting | Improves uptime and reliability |
| Cumulus Linux | Open network OS | Enables automation & scale |
| DOCA | DPU framework | Offloads CPU, boosts performance |
| UFM | InfiniBand management | Optimizes workload distribution |
4. How Does NVIDIA Networking Integrate with the NVIDIA H200 GPU?
The NVIDIA H200 GPU is built for large-scale AI and HPC workloads, and its performance depends not only on raw compute power but also on the speed of communication between nodes. This is where NVIDIA networking software tools play a critical role. By combining advanced interconnect technologies with the GPU’s high-bandwidth memory, data can move faster across the cluster, reducing delays in both training and inference. The synergy between networking and compute ensures that organizations get the most value from their NVIDIA H200 deployments.
Synergy Between Networking and H200 Hardware
The NVIDIA H200 features HBM3e memory, which provides extremely high bandwidth for data-intensive workloads. However, this advantage can only be fully realized if the GPU can quickly exchange data with other GPUs in a cluster. NVIDIA networking solutions, such as InfiniBand and software-defined tools, provide low-latency interconnects that complement H200’s memory bandwidth. Together, they minimize communication bottlenecks and improve overall workload efficiency.
Faster AI Training and Inference
When AI models are trained on multiple GPUs, the system must constantly exchange parameters and intermediate results. If the network is slow, it becomes the bottleneck. With NVIDIA networking in place, these exchanges happen at extremely high speeds, allowing H200 GPUs to perform at peak efficiency. This combination of fast interconnects and advanced GPU memory reduces training times and improves inference throughput, making it possible to deploy complex AI systems in production much faster.
Real-World Use Case
A practical example of this integration is the training of large language models such as Llama 2 with 70 billion parameters. Training such models requires hundreds or thousands of GPUs working together in distributed clusters. NVIDIA networking ensures that data is synchronized efficiently across all GPUs, while the NVIDIA H200 accelerates the compute side with its powerful memory and processing capabilities. This joint optimization makes large-scale model training feasible within reasonable timeframes.
5. What Are the Enterprise and Future Implications of NVIDIA Networking Software Tools?
Enterprises are increasingly looking at ways to modernize their infrastructure for AI, HPC, and cloud applications. NVIDIA networking software tools give them the ability to design data centers that are faster, more scalable, and more efficient. By integrating these tools with GPUs and DPUs, businesses can create AI-ready infrastructure that supports everything from large-scale model training to real-time inference in production environments.
Building AI Factories and Next-Gen Data Centers
Companies can use NVIDIA networking solutions to build what NVIDIA calls “AI factories.” These are advanced data centers designed specifically to handle the massive compute and networking demands of AI. With tools like Cumulus Linux and UFM, enterprises can automate management and optimize data flows, while BlueField DPUs offload networking and security tasks. This leads to improved utilization of resources and smoother scaling as workloads grow.
Unified AI Infrastructure for the Future
The future of AI infrastructure lies in the tight integration of networking, GPUs, and DPUs. Networking tools ensure low latency and high throughput between GPUs, while DPUs handle offloading and security. Together, they create a unified platform where compute and communication work seamlessly. This unified approach will be essential for supporting next-generation AI workloads, including generative AI, multimodal AI, and real-time decision-making applications.
Reduced Costs and Improved Scalability
NVIDIA networking tools not only boost performance but also lower the total cost of ownership (TCO). By minimizing bottlenecks and improving resource efficiency, enterprises can do more with less hardware. Scalability also becomes simpler, as networks can expand without major disruptions. This makes businesses better prepared for the demands of future AI systems while keeping operational costs under control.
Summing Up: Why Do NVIDIA Networking Software Tools Matter for the Future of AI?
NVIDIA networking software tools are essential for building the foundation of modern AI infrastructure. They ensure that data moves quickly, workloads run smoothly, and systems can scale without hitting performance limits. By combining high throughput, low latency, and intelligent management, these tools make AI and HPC environments more efficient and reliable.
Synergy with the NVIDIA H200 is especially important. The H200 delivers massive compute power and high-bandwidth memory, but without strong networking software, much of that potential could be lost to communication delays. Networking tools ensure that the GPU’s capabilities are fully unlocked, enabling faster training, optimized inference, and seamless scaling across clusters.
The key takeaway is that GPU power alone is not enough. Networking software ensures that this power is used effectively, so organizations can run large-scale workloads without bottlenecks. As AI models grow larger and data centers more complex, companies that adopt NVIDIA networking solutions will be in the best position to drive innovation, improve efficiency, and stay competitive in the long run.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now