


Platform Security Enhancements in Azure: 2026 Update
In the past year, Microsoft has made security its top engineering priority, committing to a company-wide Secure Future Initiative (SFI) and aligning product teams around…
•

Introduction: Why GenAI Deployment Needs a Strategy, Not Just Hardware
GenAI is moving fast, faster than most infrastructure plans can keep up. The dream is clear: deliver large language models (LLMs), copilots, and AI services that are responsive, scalable, and cost, efficient. But the reality? Many teams stumble because they underestimate the importance of a deliberate server deployment strategy. It’s not about buying the most expensive GPUs or chasing specs. It’s about matching the right server architecture, air, cooled, rack, optimized, or multi, GPU, to the right stage of your GenAI pipeline: development, testing, or production.
At Semifly, we’ve seen what happens when AI infrastructure decisions aren’t aligned with the realities of GenAI workloads. From teams stuck waiting for GPUs to underperforming inference clusters, the cost of poor choices isn’t just financial, it’s time lost, opportunities missed, and customers disappointed.
Let’s break down how to build a server deployment strategy that scales with your GenAI ambitions, using battle, tested systems like the HPE ProLiant XD685 with NVIDIA H200 GPUs and Dell XE9680.
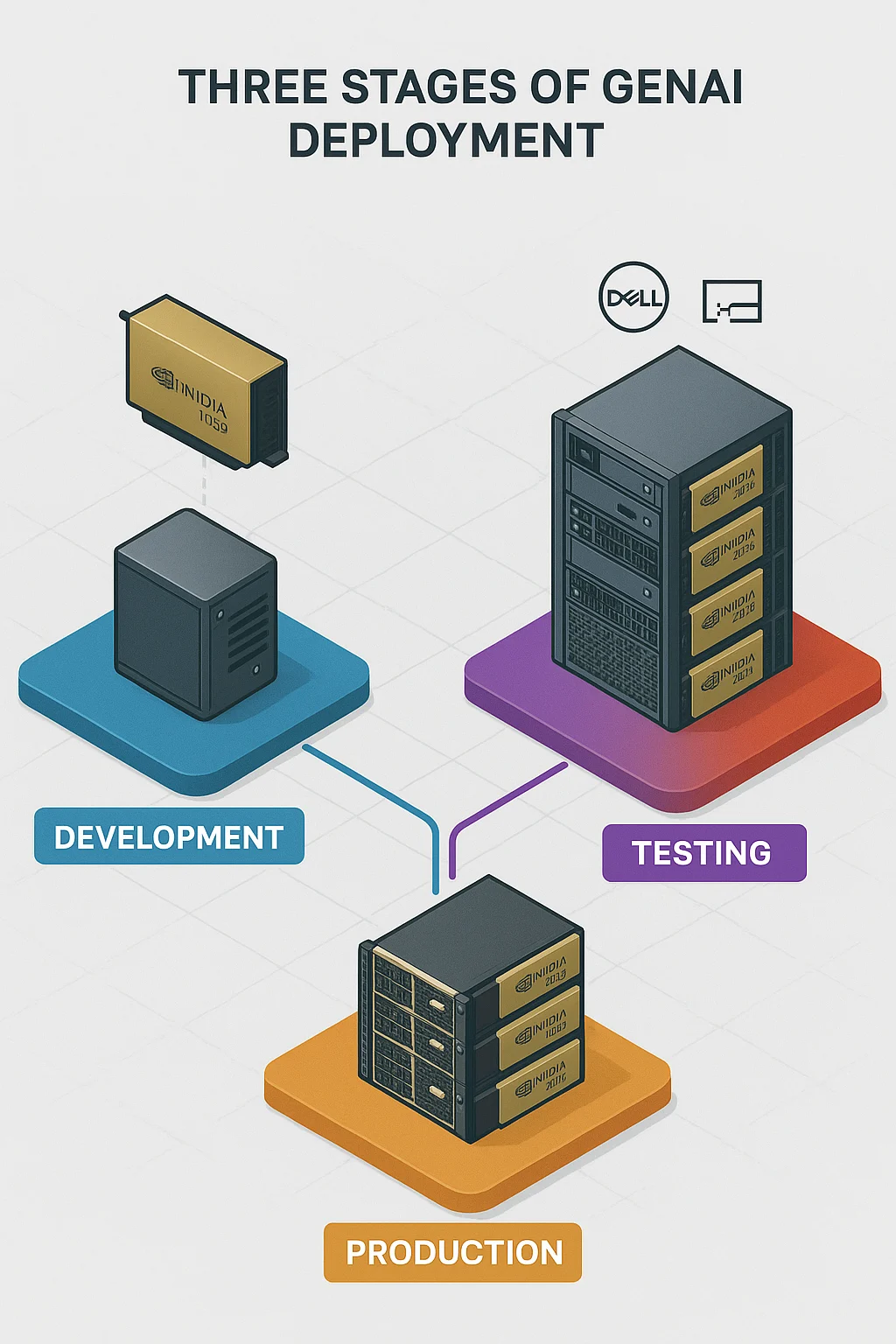
The Three Stages of GenAI Deployment: Dev, Test, and Prod
| Stage | Goal | Typical Needs | Ideal Server Choice |
|---|---|---|---|
| Development | Experiment, prototype, fine, tune small models | Flexibility, cost, efficiency, small form factor | Air, cooled, single/multi, GPU servers like Dell XE7745 or Supermicro SYS, 521GE |
| Testing | Validate performance, simulate workloads | Higher memory, multi, GPU, thermal stability | Rack, optimized servers like HPE XD685 with NVIDIA H200 for real, world stress tests |
| Production | Serve live traffic, maximize concurrency | High GPU density, bandwidth, low latency | Multi, GPU, high, memory servers like Dell XE9680 or HPE XD685 with NVIDIA H200 for scale, out inference |
Stage 1: Development, The Sandbox for GenAI Exploration
When you’re building prototypes or testing small, scale models, your priority isn’t concurrency, it’s flexibility and quick iteration. Air, cooled systems like the HPE ProLiant XD685 in a minimal configuration shine here. They allow you to experiment with fine, tuning, prompt engineering, and API integration without worrying about complex cooling or power setups.
What to focus on:
Stage 2: Testing and Pre, Production, Scaling Up, Stress Testing
As models grow and workloads intensify, so do your infrastructure demands. Rack, optimized systems like the Dell XE9680 or HPE XD685 (H200) offer the airflow, power redundancy, and I/O balance needed for real, world stress tests.
For teams running multi, tenant LLMs or exploring AI pipelines that blend inference and retrieval, augmented generation (RAG), rack, optimized designs provide:
This is where NVIDIA H200 GPUs make a decisive difference. The 141GB of HBM3e memory and 4.8TB/s bandwidth let you load larger models entirely on the GPU, eliminating memory shuffling and enabling faster, more consistent multi, model inference. Testing with H200 setups prevents surprises at scale, what works in test, works in prod.
Stage 3: Production, Scaling for High, Throughput, Always, On AI
In production, it’s all about scaling concurrency and minimizing latency. Multi, GPU servers like the HPE ProLiant XD685 with NVIDIA H200 GPUs become your go, to. The H200’s design isn’t just about raw speed, it’s about real, world throughput: running more models, serving more users, and keeping latency low even under peak demand.
For GenAI services, whether it’s an API platform, a multi, client chatbot solution, or a video generation engine, the H200 enables:
For hybrid workloads that still require some training, the Dell XE9680 remains an excellent choice, but if you’re inference, first, H200, based systems like the XD685 deliver the scale and predictability you need.

Network and Storage Considerations in GPU Server Deployment
Your GPUs are only as fast as the data they receive. For GenAI, network and storage are as critical as the GPUs themselves.
Best Practices for Networking:
Best Practices for Storage:

Why NVIDIA H200 is the Game, Changer in GenAI Server Deployments
The NVIDIA H200 isn’t just a faster GPU, it’s a solution to the exact problems GenAI workloads face at scale:
Deploying H200s in air, cooled, rack, optimized systems like the XD685 gives you the scalability, simplicity, and performance edge you need, without overcomplicating your infrastructure.
Final Thought: Design for the Workload, Not Just the Hardware
Your GenAI deployment isn’t static. What works for prototyping won’t scale to production. That’s why your server deployment strategy must evolve, starting small, testing under real, world conditions, and scaling with proven hardware like the HPE XD685 with H200 GPUs and Dell XE9680.
At Semifly, we help you make these decisions, designing AI infrastructure that aligns with your goals, not just today, but as you scale.
Ready to build a GenAI stack that works today and tomorrow?
Explore Semifly’s AI, optimized server solutions or schedule a consultation with our AI infrastructure experts to design a deployment strategy that scales with your GenAI ambitions.






We are writing frequenly. Don’t miss that.

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now