FEATURED STORY OF THE WEEK
B300 and Networking: A Technical Architecture Overview

The world of artificial intelligence is moving toward ever larger models, heavier data sets, and more demanding computational workloads. In response, organizations are building infrastructure capable of handling these demands. The arrival of NVIDIA B300 offers a new foundation for such infrastructure.
B300 delivers massive memory capacity per GPU and exceptional compute density. However, raw GPU power is only one part of the story. As GPU counts increase, and workloads span many GPUs or even multiple servers, data movement becomes a critical bottleneck. That is why combining the B300 with a carefully designed networking and interconnect architecture is essential. When B300 is paired with high-speed interconnects, the result can be a high-throughput AI infrastructure. Such infrastructure supports large-scale model training, high-speed inference, and efficient resource utilization.
In this blog, we examine how B300 works, why networking matters with high-density GPU systems, and how the integration of B300 and networking forms a solid base for modern AI infrastructure.
1. Inside the B300 Architecture
This section explains what NVIDIA B300 is under the hood. It covers its basic architecture, memory design, compute path, and the key technical features that make it suited for large-scale AI workloads.
Overview of the B300 GPU
The B300, also known as Blackwell Ultra, builds on the lineage of previous Blackwell generation GPUs.
Instead of aiming for minimalism, the B300 is designed to serve heavy AI workloads. Each B300 GPU carries large on-package memory. This design lets the GPU hold big models and large data batches entirely in fast GPU memory, reducing reliance on slower systems or storage memory.
The high-bandwidth compute path inside B300 is engineered for tensor operations common in machine learning. The internal fabric allows data and tensors to move quickly between compute units inside the GPU, and across GPUs when used in multi-GPU systems.
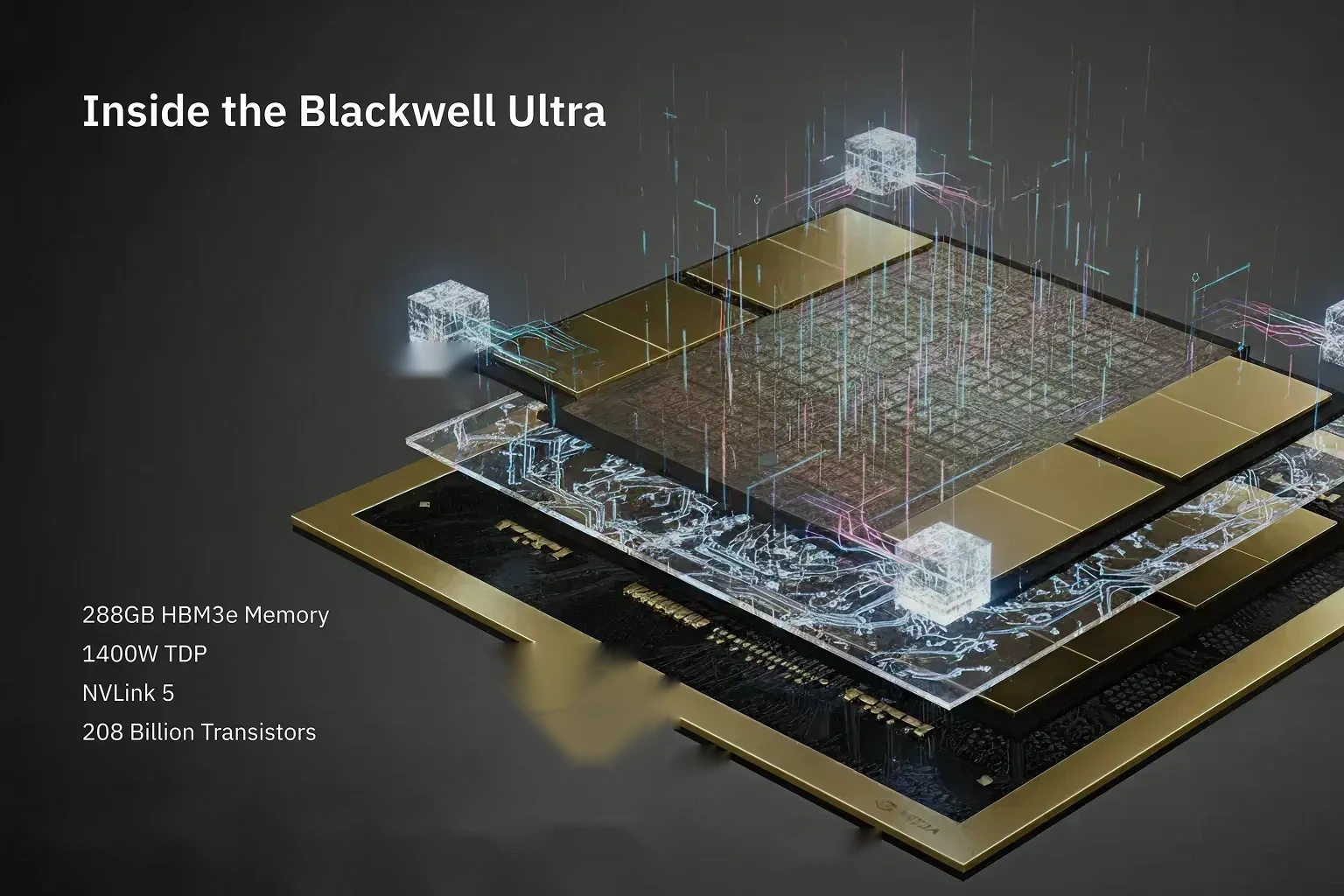
These features give B300 the infrastructure to handle large models, big batches, and heavy compute without being shackled by external memory or I/O bottlenecks.
Key Architectural Highlights
HBM3e Memory Layout
- Each B300 GPU is equipped with 288 GB of HBM3e memory. This is a substantial increase compared to prior-generation GPUs with lower memory capacity.
- The memory is implemented as 12-high HBM3e stacks, compared to 8-high stacks in older generations.
- The large memory enables models with large parameter counts, larger input batches, longer context windows, and reduces the need for frequent data movement to slower tiers.
- HBM3e is a stacked memory architecture optimized for high-throughput and low-latency data access. Using HBM3e means that data transfer speed between memory and GPU cores is much higher than with standard DDR or older GPU memory types.
Power Characteristics
- B300 GPUs carry a significant thermal/power design. Reported TDP for B300 is about 1400 W per GPU. This elevated power allowance supports dense memory and heavy compute logic.
- The power characteristic reflects B300’s role: it is not designed for low-power edge deployments, but rather for high-performance data center or large compute-cluster environments, where infrastructure can support the required cooling and power delivery.
Tensor Compute Capability
- B300 offers significantly higher compute throughput than its predecessor. It delivers roughly 50% more AI compute performance than the prior-generation B200.
- With support for modern tensor formats (e.g., low-precision tensor operations), B300 is tailored for workloads typical in machine learning, such as large language model training, inference, and large-batch data processing.
- In multi-GPU system builds, aggregate compute throughput becomes massive. This enables heavy workloads without frequent data offload to CPUs or storage.
Large-Model Performance Impact
- The combination of large GPU memory and high compute throughput allows B300 to handle huge models in a single GPU or across a multi-GPU system. This reduces overhead from data sharding or frequent memory transfers.
- Models that in older architectures required splitting across many GPUs may now fit wholly within GPU memory. This simplifies model management and may improve execution speed and latency.
- For inference workloads, especially those sensitive to latency (e.g., real-time responses, high-throughput serving), having enough memory and compute on the GPU reduces dependency on slower storage layers.
Why B300 Depends on Fast Networking
When deploying powerful hardware like NVIDIA B300, compute performance alone does not guarantee efficient AI workloads. As soon as workloads span multiple GPUs, data movement becomes a critical factor. This section explains why B300 and networking must be treated as a joint concern, not separate parts.
Scaling AI Across Nodes
Large AI models often exceed the memory or compute capacity of a single GPU. To handle such models, many organizations distribute the model across multiple GPUs, and sometimes across multiple servers. This is known as distributed model training. In such a setup, different GPUs process different parts of data and periodically exchange information: gradients, parameters, activations, etc.This exchange requires synchronization among GPUs. In multi-GPU systems, frameworks like PyTorch Distributed Data Parallel or similar rely on synchronization at each training step to ensure consistency. If the network is slow or congested, GPUs spend time waiting for data instead of computing.
The result: high compute power sits idle, and training takes longer. For a high-performance GPU like B300, which is capable of handling large workloads rapidly, such waiting time can erase much of the performance advantage. That is why network bandwidth (how much data can move per second) and latency (how quickly a message gets from A to B) become critical. Low bandwidth or high latency can turn a multi-GPU cluster into a bottleneck, no matter how powerful the GPUs are.
The Interconnect Layer Explained
To see how networking supports B300-based deployments, it helps to break down communication into two main layers: within a node (GPU-to-GPU) and across nodes (node-to-node).
GPU-to-GPU Communication (Intra-Node)
Inside a server that houses multiple B300 GPUs, GPUs need to share data continuously during training or inference. For this, high-speed interconnects like NVLink provide direct, low-latency, high-bandwidth links. NVLink allows much faster communication than traditional PCIe-based transfers.
This makes a big difference. With high interconnect bandwidth, data moves fast between GPUs. The system can treat multiple GPUs as a unified compute resource. For B300, this ensures that the large memory and compute cores on each GPU can work in concert without being bottlenecked by slow inter-GPU transfers.
Node-to-Node Links (Inter-Node Networking)
When workloads span across multiple servers, you need high-performance external networking. This covers data exchange between servers — for model synchronization, data loading, checkpoint saving, or distributed inference. Without efficient networking, clusters suffer from latency and bandwidth limitations that degrade performance. Modern AI clusters often use networks that support high throughput and low latency. For example, RDMA enables direct memory transfers between servers without involving CPUs.
This reduces overhead and latency. In larger deployments, advanced network fabrics may provide multi-plane connectivity. For example, the reference fabric design for large clusters built around B300 uses a dual 400 GbE connectivity per GPU, across two independent planes. This enhances both performance and fault tolerance. Such designs ensure that even as clusters scale to dozens or hundreds of nodes, network performance remains sufficient to support high-speed data exchange, synchronization, and consistent throughput.
3. B300 Interconnect and Data Path
This section examines how NVIDIA B300 works under the hood, in particular, how data travels both inside a server and across servers when B300 GPUs are deployed in modern AI infrastructure.
Internal GPU Fabric
B300 uses high-speed internal interconnects to tie multiple GPUs together inside a server.
- The internal fabric relies on NVLink, specifically NVLink 5, along with NVSwitch to enable communication among GPUs. In configurations like NVIDIA DGX B300, two NVLink Switch Systems are used.
- NVLink 5 provides very high per-GPU bandwidth. Each B300 GPU supports up to 1.8 TB/s bidirectional GPU-to-GPU interconnect bandwidth.
- This high-bandwidth fabric enables all GPUs in the server to share data and memory state quickly. For workloads such as large-model training or inference, this means that tensors, activations, gradients, or model parameters can move across GPUs without needing to route them through the CPU or slower system memory.
- With this design, a multi-GPU server can behave like a consolidated compute and memory resource — important when models exceed the capacity of a single GPU. In systems like DGX B300, this internal connectivity complements the large HBM3e memory per GPU to deliver unified performance.
External Fabric and Ports
High internal GPU connectivity must be paired with a strong external network when workloads span beyond a single server. B300-based systems provide several external networking options to support multi-node clusters, distributed training, and data exchange.
- A DGX B300 system includes 8 OSFP ports, each connected to a dedicated network adapter, NVIDIA ConnectX-8 VPI, enabling cluster-level networking.
- These ports support up to 800 Gb/s InfiniBand or Ethernet, enabling high-bandwidth data exchange between nodes.
- For additional networking, DGX B300 includes dual-port network devices — e.g., NVIDIA BlueField-3 DPU — which can be used for storage, management, or alternative data-path networking.
- In larger installations — for example, a multi-node cluster or rack-scale system based on B300 — designers often adopt a fabric architecture. For network fabrics using 400 GbE or InfiniBand, multi-plane fabric designs help provide both performance and redundancy. In such a design, each GPU/node may have multiple independent network paths operating in parallel.
What this external fabric enables:
- Efficient data exchange across servers, which is necessary for distributed model training, parameter synchronization, and data sharding.
- High-throughput data movement to match the rate at which B300 GPUs consume and produce data.
- Flexibility in network topology. Engineers can choose between InfiniBand or Ethernet depending on performance, cost, and existing data center infrastructure.
- Support for advanced workflows. DPUs can offload networking, storage, or security tasks, thus relieving CPU and GPU from extra overhead.
- 4. B300 in NVIDIA System Platforms
This section looks at how NVIDIA packages the NVIDIA B300 into real-world systems, from a single server to rack-scale platforms, and what that means for AI infrastructure.
DGX B300 Architecture
Shortly after the B300 became available, NVIDIA introduced the NVIDIA DGX B300 as a turnkey AI appliance.
- 8-GPU Configuration: DGX B300 comes with eight B300 GPUs, all mounted in an SXM form factor.
- Total GPU Memory: The system offers around 2.1 TB of HBM3e memory that enables large models or high-batch workloads on a single appliance.
- Compute Performance: DGX B300 supports up to 144 PFLOPS (FP4 inference) or 72 PFLOPS (FP8 training) in dense configurations.
- Internal Interconnect: The system uses 2x NVLink Switch Systems, delivering an aggregate GPU-to-GPU interconnect bandwidth of 14.4 TB/s.
DGX B300 Networking and External Connectivity
- The DGX B300 offers 8 OSFP ports, each mapped to a single-port NVIDIA ConnectX-8 VPI adapter, giving high-bandwidth node-to-node connectivity.
- Additionally, there are dual-port QSFP112 devices (e.g., NVIDIA BlueField-3 DPU) for data-path networking, offering options for InfiniBand or Ethernet at substantial bandwidths.
- The appliance is designed as a 10U rack unit, with a power consumption of roughly ~14 kW.
DGX B300 offers a unified, turnkey platform that combines the B300 GPU architecture with high-speed interconnect and networking. For organizations evaluating AI infrastructure, it provides a predictable, supported building block, which is ideal for training large models, inference workloads, or as a node within a larger cluster.
HGX B300 at Rack Scale
For deployments that demand higher density, flexibility, or custom integration, NVIDIA also supports B300 through its NVIDIA HGX B300 reference platform.
- Modular 8-GPU Servers: HGX B300 uses server trays or modules that house 8x B300 GPUs, each with 288 GB HBM3e, tied together with NVLink / NVSwitch.
- Flexible Deployment Types: Vendors offer both air-cooled (8U) and liquid-cooled (4U) variants, depending on thermal and rack constraints.
- Rack-Level Aggregation: Multiple HGX B300 servers can be grouped in racks. Some vendor solutions offer RackScale 32 — i.e., four compute servers (total 32 GPUs) sharing a common rack-level network and storage configuration.
- The platform also supports high-performance networking with external fabrics using ConnectX-8 NICs, enabling multi-node cluster communication.
- The same NVLink / NVSwitch GPU interconnect inside each node ensures that GPUs within a server act as a unified resource.
HGX B300 is designed for large-scale AI workloads, e.g., training large language models, large-batch inference, multi-modal AI, real-time reasoning, and HPC-like workloads.
Because the platform is modular, data center operators can deploy HGX B300 units gradually, build up rack-scale clusters over time, or tailor the configuration to their infrastructure constraints.
What the Two Platforms Offer in Practice
- The DGX B300 is ideal when you want a ready-to-deploy, supported appliance. It gives predictable performance and integrates GPU, interconnect, networking, and storage in a packaged solution.
- HGX B300 suits environments where flexibility or scale matters, e.g., building a custom AI cluster, integrating into existing data center infrastructure, or scaling over time.
- 5. Data Center Networking with B300
B300 delivers high compute density and very high GPU-to-GPU bandwidth inside the server. To realize that performance at the cluster scale, the data center network must support the same level of throughput and low latency across nodes.
Network Fabric Design
Data center fabrics for B300 and networking are often built using a leaf-spine topology. In this topology, every B300 node connects to one or more leaf switches. The leaf switches then connect to a set of spine switches.
This creates a predictable path for any node to communicate with any other node through two network hops. Leaf-spine is common in modern GPU clusters for its stable path length and reduced network contention.

A tiered network architecture builds on this base model. In small clusters, a single tier of leaf and spine switches is often enough. As clusters grow, additional tiers help manage port density and bandwidth. This matters for B300 because each node has multiple 400–800 Gb/s ports. At that scale, a single tier may not have enough ports or bandwidth headroom. Software frameworks for distributed training expect predictable communication patterns.
The tiered design supports this by maintaining consistent path latency as nodes increase.Latency and congestion handling are also central to B300 deployments. In distributed training, collective communication often uses all-reduce operations. These operations send and receive data between all GPUs participating in a training step. Any congestion in the path delays the entire step. InfiniBand fabrics offer features like congestion control and low-latency switching that are useful for this workload. Ethernet fabrics can use RDMA over Converged Ethernet to provide similar characteristics, along with traffic management in the switch.
NVIDIA recommends congestion management and multi-plane design for large B300 clusters to maintain stable throughput.In practice, the fabric must match the speed at which B300 GPUs exchange data. Inside the server, B300 offers up to 1.8 TB/s bidirectional NVLink bandwidth per GPU, which places pressure on the network to support high throughput beyond the chassis. High-performance fabrics help avoid cases where GPU compute waits on slower network links.
Deployment and Infrastructure
Port density and rack layout influence how many B300 nodes can fit in a rack and how they connect to the network. A DGX B300 has 8 OSFP ports, each linked to a dedicated NVIDIA ConnectX-8 network adapter. This provides high throughput from each node into the network fabric. The DGX B300 design document shows the 10U chassis with power and cooling support suitable for the high thermal load of eight B300 GPUs.
This port layout means a single rack may aggregate many high-bandwidth links. Designers must account for switch port counts, cable routing, and overhead space for airflow. As the number of GPU nodes grows, the fabric may need more spine switches or secondary tiers to handle all ports while keeping hop counts stable.Cooling and power considerations are important in B300 deployments. A single B300 GPU has a reported thermal design point of about 1400 W.
Eight GPUs in a DGX B300 can require around 14 kW for the server alone. High-bandwidth network adapters add to the load. Data centers planning for B300 clusters should estimate power and cooling per rack based on these figures. Facilities may use liquid cooling in some deployments, especially at higher rack densities. NVIDIA’s DGX and HGX specifications provide guidance on airflow and thermal requirements for B300-based systems.Choosing InfiniBand or Ethernet depends on the deployment scale and the existing network environment.
- InfiniBand is common in large training clusters because it provides low latency, high bandwidth, and built-in support for collective communication. It also offers advanced congestion control. These features are helpful in multi-node training involving all-reduce operations.
- Ethernet with RoCE is often selected when the organization already runs high-bandwidth Ethernet in the data center. RoCE provides RDMA support on Ethernet, reducing CPU involvement and lowering latency. High-performance switches can provide the traffic management needed for distributed AI workloads.
- 6. Practical Use Cases
With the architecture, interconnect, and networking foundations in place, hardware based on NVIDIA B300 becomes useful for real-world AI workloads. Below are two broad categories where a B300-backed infrastructure delivers clear advantages.
Large-Scale Model Training
In large AI model training, especially for deep learning or large language models, training is often distributed across multiple GPUs or servers. In a B300-based cluster, individual GPUs or entire B300 nodes work together in a synchronized fashion.
During training, the workflow involves frequent parameter exchange and gradient sharing among all participating GPUs. This data exchange must happen rapidly and repeatedly. With B300, the high internal GPU-to-GPU bandwidth and external network fabric ensure that this data flow does not become a bottleneck.Because each B300 GPU carries large HBM3e memory, large models may fit within a single GPU or a small multi-GPU set.
This reduces the complexity of model sharding and simplifies memory management. As a result, training becomes more efficient, with less overhead due to cross-GPU or cross-node memory transfers.For organizations training very large models, using B300 with an appropriate network fabric supports high throughput and consistent performance across training runs. This can shorten training cycles, improve resource utilization, and lower the operational complexity when compared to older, memory-constrained GPU architectures.
Multi-Node Inference at Scale
Large-scale inference, for example, serving responses from a large language model or AI-driven application, benefits significantly from the combined compute and networking capabilities of a B300 cluster.When inference load is high, requests may need to be distributed across multiple GPUs or servers. A B300-based cluster can serve large models that do not fit on smaller GPUs. The high GPU memory ensures the full model stays resident in GPU memory.
That reduces the latency that might arise from swapping data between the GPU and the CPU or from accessing slower storage.With strong external networking, multiple nodes can work together to handle high-volume inference traffic. Fast data paths among nodes help distribute input data, collect results, and manage workloads without excessive delay. This makes B300 a good fit for applications that demand both large model capacity and low-latency responses, such as real-time language models, large-scale recommendation engines, or high-throughput AI services.
Summing Up
The value of NVIDIA B300 becomes clear when it is viewed together with the network that supports it. The GPU delivers high memory capacity and strong tensor compute, but real performance in large AI environments depends on how fast GPUs can exchange data. That makes B300 and networking a combined design topic rather than separate areas.Inside the server, NVLink and NVSwitch allow B300 GPUs to share parameters and activations at high speed.
Across servers, high-bandwidth fabrics such as InfiniBand or Ethernet with RDMA support maintain low latency during training. For enterprises building AI platforms, the conclusion is clear: B300 delivers its full capability only when supported by a well-planned network fabric. When hardware and network design align, B300 can support large model training, multi-node inference, and production AI workloads at a meaningful scale.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now