FEATURED STORY OF THE WEEK
NVIDIA Blackwell Ultra GPUs - Pillar of moder datacenters

If you talk to any infrastructure team today, the conversation isn’t just about “more GPUs.” It’s about how efficiently every token can be generated. That’s the new metric the industry quietly moved toward over the last 18 months. AI models have evolved now, and they reason, plan, and execute multi-step tasks, dramatically increasing compute demands. Traditional scaling strategies, such as adding more GPUs, no longer meet economic or performance requirements. Consider this: a $5 million GB200 NVL72 system can generate $75 million in token revenue, a 15× return on investment. This gain comes from efficiency, tokens per watt, and cost per million tokens. Blackwell Ultra (B300) is built for this reality. It delivers:
- Higher tokens-per-watt for energy-efficient inference
- Lower cost-per-million-tokens for sustainable margins
- Hardware optimized for real-time reasoning, beyond batch training
NVIDIA DGX B300 System is not only an upgrade, but a platform designed to make large-scale, high-efficiency AI deployments practical and economically viable. In this blog, we’ll walk through how NVIDIA achieved that, covering the architectural improvements, and the enterprise capabilities that position Blackwell Ultra as the new standard for AI infrastructure.
Compute Reimagined: What Makes Blackwell Ultra Different
Before we get into how NVIDIA redesigned the architecture, let’s quickly look at how Hopper and Blackwell Ultra differ at a fundamental level.
Blackwell Ultra vs. Hopper
| Capability | Hopper H100/H200 | Blackwell Ultra B300 | Improvement |
| Core Architecture | Monolithic GPU | Dual-die unified GPU | Breaks scaling limits |
| Transistor Count | ~80B | 208B | ~2.5× increase |
| Precision Format | FP8 | NVFP4 | New format optimized for inference |
| Dense Throughput | ~2 PFLOPS (FP8) | 15 PFLOPS (NVFP4) | 7.5× |
| Memory | 80–141 GB | 288 GB HBM3e | Up to 3.6× |
| Attention Execution | Standard | 2× faster | Lower latency |
Blackwell Ultra’s 7.5× performance gain over Hopper isn’t the result of a single architectural change. It comes from solving three constraints that directly limited inference throughput, context length, and real-time reasoning performance in previous-generation systems. Let’s understand the B300 through these three engineering forces.
- Scaling Beyond a Single Die
Modern models have outgrown what a monolithic GPU die can deliver. Hopper was already pushing reticle limits, and increasing transistor counts further would have resulted in reduced yields and higher costs. Blackwell Ultra overcomes this ceiling by moving to a dual-die GPU architecture with 208 billion transistors.Both dies operate as a unified compute surface thanks to:
- 10 TB/s NV-HBI interconnect, enabling near-monolithic latency and bandwidth
- A shared memory subsystem and synchronized execution model
- Cross-die scheduling that treats the pair as a single GPU
This approach enables performance scaling that was previously impossible with a single piece of silicon.
- Precision and Throughput for Reasoning Workloads
Inference workloads today require higher throughput at lower precision but without sacrificing accuracy. Blackwell Ultra addresses this with the introduction of NVFP4, a new 4-bit floating-point format optimized specifically for large-scale transformer inference.Key outcomes:
- 15 PFLOPS dense NVFP4 throughput, a 7.5× uplift over Hopper FP8
- ~1.8× reduction in memory footprint compared to FP8
- Near-FP8 accuracy through second-generation Transformer Engine optimizations
This isn’t only about faster execution. Smaller footprints translate into lower memory costs, reduced latency, and the ability to run larger models within a single GPU, all of which directly impact inference economics.
- Memory, Context, and Interactive AI Performance
Modern AI agents rely on extended context windows, faster attention mechanisms, and large-scale parameter hosting. Blackwell Ultra increases both memory capacity and attention performance to support these demands.
- 288 GB HBM3e per GPU over 3.5× more than H100
- 2× faster attention computation, accelerating softmax and context mixing
- Improved end-to-end latency for real-time and interactive workloads
The result is a platform capable of running trillion-parameter models and multi-million-token contexts without sharding overheads or offloading penalties.
Datacenter Readiness: Power, Cooling & Cost Realities
As GPU performance increases, datacenter design must evolve with it. Blackwell Ultra makes this shift explicit: the power and cooling requirements that once applied only to specialized deployments are now the baseline for any AI-capable facility. Instead of treating cooling as a constraint, it’s more accurate to view it as part of the core infrastructure required to operate modern AI systems at scale.
Designing for 1,400W GPUs
Blackwell Ultra pushes GPU power density to levels that previous datacenter standards weren’t built to handle:
- Up to 1,400W TGP, nearly double the thermal envelope of H100
- Power density that exceeds the limits of traditional air-cooled rack designs
- Heat dissipation patterns that require coolant-level thermal transfer rates
Direct Liquid Cooling (DLC) has become the operational baseline for running Blackwell Ultra in high-density environments. Facilities built for Hopper-era GPUs must account for this shift if they plan to deploy NVL-scale systems.
The TCO Equation for Liquid Cooling
Integrating DLC adds upfront cost, but the operational economics quickly offset it. For example, an NVL72 rack includes approximately $49,860 in dedicated DLC hardware: cold plates, manifolds, heat exchangers, and supporting components.What matters is what this investment unlocks:
- Up to 25× more performance at the same power budget compared to air-cooled H100 clusters
- As much as 40% lower electricity costs due to higher cooling efficiency and reduced reliance on traditional HVAC systems
Higher power density typically implies higher operational costs; with DLC, the opposite occurs. Blackwell Ultra’s cooling ecosystem converts thermal challenges into efficiency gains, ultimately lowering OpEx even as compute density increases.
From a Single GPU to a Full AI Fabric: How Blackwell Actually Scales
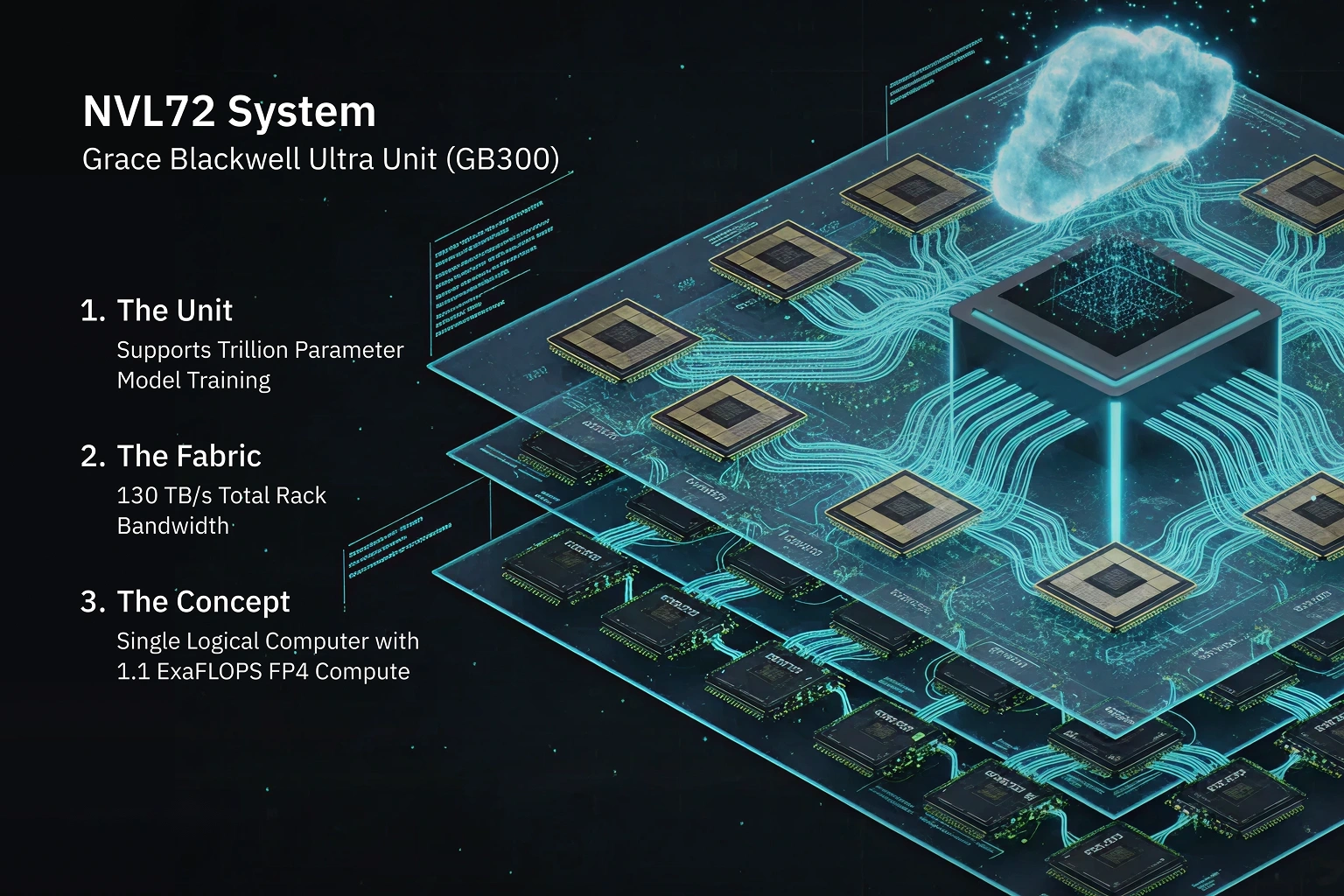
Blackwell doesn’t scale the way traditional GPU systems do. Instead of treating each processor as a standalone unit, it extends the idea of locality across an entire rack. The result is a continuum from one module to a full AI fabric where compute, memory, and interconnect behave like one organism rather than a cluster of parts.Image2_alt_text_ Layered diagram showing 72 B300 GPUs and 36 Grace CPUs operating as a single 1.1 exaFLOPS logical computer

The Grace Blackwell Ultra Unit (GB300)
At the smallest level, everything begins with the GB300:1 Grace CPU + 2 Blackwell Ultra GPUs, connected through NVLink-C2C at 900 GB/s.This is the foundational module NVIDIA uses to guarantee high-bandwidth coherency between CPU and GPU without penalties from PCIe bottlenecks. If you understand the GB300, you essentially understand Blackwell’s design philosophy: collapse distance, increase shared bandwidth, and treat memory as a single extended pool.
NVL72: When a Rack Becomes a Fabric
Scale that atomic unit up, and you reach the NVL72:72 Blackwell Ultra GPUs + 36 Grace CPUs operating as a single logical computer.The NVLink Switch Chip enables 130 TB/s of rack-scale bandwidth, allowing all 72 GPUs to remain in a coherent domain, no discontinuities, no traditional cluster fragmentation. The result is a rack with:
- 1.1 exaFLOPS of FP4 compute
- Automatic workload distribution as if the entire rack were a single GPU
- Predictable scaling for models that previously broke across nodes
NVL72 is where the architecture stops looking like a cluster and starts behaving like an AI fabric purpose-built for trillion-parameter model training and real-time inference systems.
Enterprise-Strength Features: Security, Data, and Reliability Built In
As Blackwell scales outward, the platform also becomes more than a performance story. It has to satisfy the operational realities of enterprises handling sensitive data, strict uptime requirements, and massive analytics pipelines. This section brings those capabilities into one place, features that matter when GPUs move from the lab to regulated, production-grade environments.
Confidential Compute Without Throughput Penalties
With Blackwell, NVIDIA brings TEE-I/O directly onto the GPU, enabling encrypted compute in a way that doesn’t feel like an optional add-on. Sensitive data never leaves the trusted boundary, and importantly, there’s near-zero performance loss even when workloads remain fully encrypted.For industries where compliance determines what can or cannot run on GPU infrastructure like healthcare, finance, government workloads- this shifts the conversation from “is it allowed?” to “it performs just as well.”
Data Movement and Reliability at Scale
Modern AI systems are as much about moving data as they are about processing it, and Blackwell supports both sides of that equation.
- A dedicated decompression engine (supporting LZ4, Snappy, Deflate) removes the burden from CPUs and accelerates data-heavy pipelines, analytics, retrieval-augmented generation, feature engineering, and more.
- The RAS engine adds AI-driven telemetry for predictive fault detection, reducing unplanned downtime and allowing teams to maintain large GPU clusters with confidence.
Together, these components strengthen the platform’s operational backbone. They ensure that as compute scales, the data path and system reliability scale with it without hidden overhead or architectural compromises.
NVIDIA’s Full-Stack Advantage and the Road Ahead
The long-term value of Blackwell Ultra comes from how well it integrates with NVIDIA’s software stack and roadmap. This alignment determines how the platform evolves after deployment and how much incremental performance organizations can capture over time.
Software Continuity and Post-Launch Performance Gains
NVIDIA maintains absolute CUDA compatibility, ensuring that applications, frameworks, and internal tooling transition seamlessly to Blackwell Ultra. With CUDA Toolkit 13.0, FP4 support and updated Tensor Cores are fully integrated, enabling immediate efficiency gains for inference-heavy workloads. Performance doesn’t plateau at deployment. TensorRT-LLM, NVIDIA Dynamo, and continuous compiler improvements unlock additional throughput over the hardware’s lifecycle. These incremental releases compound overall efficiency, reducing cost per inference without requiring new infrastructure.
Supply, Procurement, and the Architecture Cadence
Initial availability in Q4 2025 will be shaped by constraints in HBM3e and CoWoS-L packaging, prioritizing hyperscale and early enterprise demand. Organizations planning large-scale adoption should expect a staggered procurement cycle.The roadmap advances in Q2 2026 with Rubin (R200), the first architecture designed around HBM4. In this transition, Blackwell Ultra serves as the bridge, delivering the required uplift today while aligning with the memory and packaging standards that define the next generation.
Accessing Blackwell Ultra Through the Semifly Marketplace
For teams planning Blackwell Ultra deployments, procurement efficiency becomes part of the overall infrastructure strategy. The Semifly Marketplace provides a centralized path to evaluate configurations, compare deployment options, and coordinate delivery timelines, particularly important given early supply constraints. Key advantages include:
- Access to validated Blackwell Ultra configurations and NVL72 rack options
- Guidance on power, cooling, and datacenter readiness
- Coordination with NVIDIA’s availability cycles to streamline procurement
If you are looking for assistance with planning or readiness assessments, book a free call to discuss deployment requirements and timelines.
Final Word
Blackwell Ultra marks a shift in how AI infrastructure is evaluated, moving from raw speed to efficiency, scalability, and long-term operability. Its architecture, software alignment, and datacenter requirements define a platform built for sustained growth, not short-cycle gains. For organizations preparing for larger models, faster inference, and higher-density deployments, Blackwell Ultra represents the new baseline for the next generation of AI systems.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now