FEATURED STORY OF THE WEEK
H200 vs H100 GPU Memory: Which One Is Better for AI Workloads?

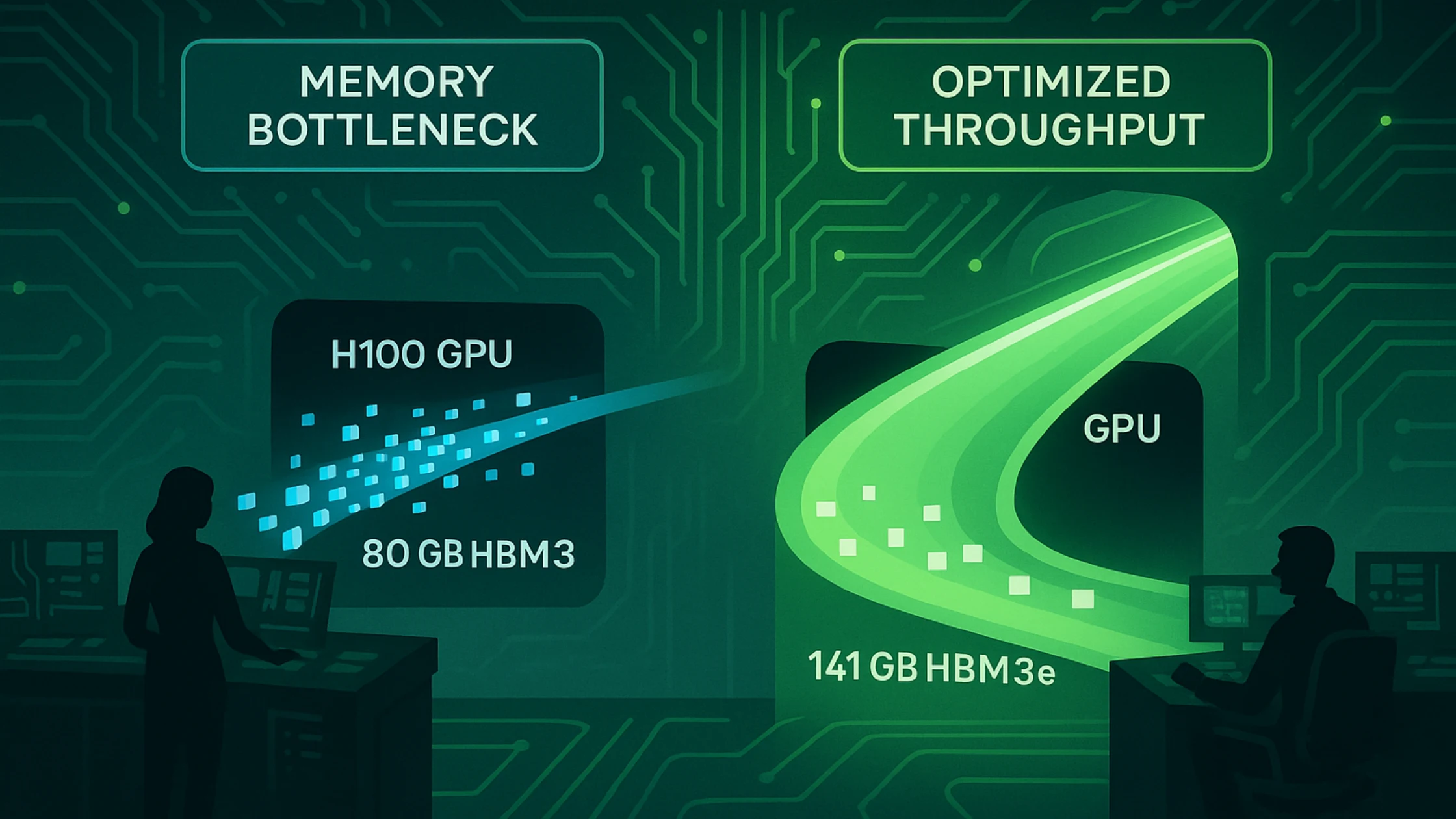
Why Is GPU Memory Now the Biggest Bottleneck in AI?
A CIO recently hit a latency wall during a 128K-token LLM inference demo. Despite strong compute capacity, context window retention collapsed due to memory starvation.
Modern AI workloads have evolved: It’s no longer about raw FLOPS. The real constraint is memory—how much you can hold in-cache, and how fast it can be accessed.
Inference reliability, user concurrency, and GenAI UX now depend more on memory bandwidth and size than training power. This is where the NVIDIA H200 redefines limits.
What Are the Key Specs That Differentiate H200 and H100?
| GPU | Memory Type | Capacity | Peak Bandwidth | Transformer Engine | Launch Year |
|---|---|---|---|---|---|
| H100 | HBM3 | 80 GB | 3.35 TB/s | Gen 1 | 2022 |
| H200 | HBM3e | 141 GB | 5.2 TB/s | Gen 2 | 2024 |
The H200 adds 76% more memory and 1.5x bandwidth—giving LLMs breathing room.
Does 141 GB HBM3e Outperform 80 GB HBM3 for Real LLMs?
Let’s look at memory residency for real model pipelines:
| LLM Size | KV-Cache per 1K Tokens | Fits in H100? | Fits in H200? |
|---|---|---|---|
| 13B | 8 GB | Yes | Yes |
| 65B | 38 GB | Multi-GPU | Yes |
| 70B + Embeddings | 64–80 GB | No | Yes |
Real-world example: One Semifly client avoided a 2× GPU split in RAG + vision pipelines by upgrading to H200.

How Does Memory Bandwidth Impact Token-Level Latency?
Memory bandwidth affects how quickly GPUs can load KV-cache and retrieve context during attention operations. Token delays under load lead to jitter and inconsistency.
| Token Window | H100 Latency (ms) | H200 Latency (ms) | Improvement |
|---|---|---|---|
| 64K | 112 | 76 | 32% faster |
| 128K | 198 | 111 | 44% faster |
H200’s 5.2 TB/s HBM3e enables smoother attention head traversal under scale.
How Do H200 and H100 Perform in Enterprise GenAI Inference?
Enterprise use cases—like multi-tenant chatbot farms and RAG pipelines—depend on:
- Consistent latency
- Higher session concurrency
- Memory-persistent batching
With NVLink 4.0 and 141 GB memory, the H200 reduces cold start penalties and model duplication. It supports:
- 160+ concurrent users on Llama 2–13B
- Persistent token context for multi-turn interactions
Fewer model copies also mean:
- Lower licensing risk
- Tighter cost controls
- Simpler observability dashboards
Can HPC and FP8 Training Workloads Benefit from H200?
Absolutely. CFD simulations, genomics pipelines, and hybrid FP8 workloads gain throughput benefits from higher memory bandwidth.
Example: GPT-3 13B fine-tune
- H100: 6,200 tokens/sec
- H200: 9,400 tokens/sec (1.5x)
More memory also improves:
- Checkpoint management
- Large-batch training
- Memory-efficient precision stacking

Which GPU Should You Choose for Your Workload?
| Workload | Latency Target | Dataset Size | Best GPU | Rationale |
|---|---|---|---|---|
| Internal Chatbot (64K) | < 120 ms | Medium | H100 | Fits in 80 GB |
| Public GenAI (128K) | < 100 ms | Large | H200 | Needs 141 GB + bandwidth |
| Finetune 70B Model | Throughput | Large | H100 | Multi-GPU training centric |
| RAG + Vision GenAI | Consistency | Extra Large | H200 | Multi-modal, memory heavy |
For real-time inference workloads, H200 saves cost by eliminating over-provisioning.
How Does Semifly Help You Deploy Memory-Optimized H200 Clusters?
Semifly helps enterprises turn memory-optimized GPUs into scalable, turnkey infrastructure. Our offering includes:
- Pre-clustered DGX-H200 with NVLink interconnect
- NeMo and Triton stack integration tuned for memory-bound LLMs
- RAG-ready cluster deployments
- GPU memory profiling and observability dashboards
- Cost-per-user modeling to optimize hardware ROI
- H200 marketplace pricing and availability
Final Takeaway
In 2025, memory is the new AI performance ceiling. The NVIDIA H200 offers:
- 141 GB HBM3e memory
- 5.2 TB/s bandwidth
- Gen 2 transformer engine
If you’re scaling chatbots, RAG, multimodal agents, or GenAI APIs, H200 gives you the memory headroom to stay fast, compliant, and cost-efficient.
Book your H200 memory profiling session with Semifly and scale with confidence.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now