FEATURED STORY OF THE WEEK
High Throughput Batch Inference with NVIDIA H200: Unlocking Scalable AI Performance

Introduction: Throughput as the True AI Bottleneck
In AI, performance isn’t just about raw compute. It’s about how efficiently you can translate GPU horsepower into end-to-end throughput — measured not in FLOPs, but in tokens per second, inference requests served, and cost per workload.
That’s why High Throughput Batch Inference has become the defining challenge for enterprises deploying LLMs and generative AI at scale. Whether it’s serving real-time customer interactions, powering multi-tenant inference clusters, or processing millions of retrieval queries per hour, the infrastructure either scales linearly — or collapses under bandwidth and latency bottlenecks.
Enter the NVIDIA H200, with 4.8 TB/s of memory bandwidth and 141 GB of HBM3e memory per GPU. These capabilities shift the economics of inference: where older GPUs forced compromises between batch size, latency, and cost, the H200 enables enterprises to handle high-throughput workloads with efficiency and predictability.
At Semifly, we specialize in turning those specs into real-world business outcomes. This blog unpacks how H200 throughput transforms batch inference and what it takes to architect clusters that actually deliver on the promise.
Why Throughput Matters More Than FLOPs
Every enterprise deploying AI faces the same dilemma: models are growing larger, but customer expectations demand faster responses at lower costs.
- Batch inference is the lever: serving multiple requests simultaneously to amortize compute and memory costs.
- Throughput determines viability: how many requests per second the infrastructure can sustain without breaking SLAs.
- Inefficiency compounds quickly: 10% GPU underutilization in a 1,000-GPU cluster equates to millions in wasted OPEX annually.
The NVIDIA H200 directly addresses these pain points: higher sustained memory throughput means models spend less time waiting for data, and more time generating results.
How H200 Throughput Powers Batch Inference
The H200 is purpose-built for high-throughput AI inference. Its core features map directly to batch-serving demands:
- 141 GB of HBM3e: Large context windows (16K–32K tokens) and multi-batch inference streams fit directly into GPU memory, avoiding DDR or PCIe paging.
- 4.8 TB/s Bandwidth: Ensures activations, embeddings, and weights move fast enough to keep Tensor Cores saturated.
- FP8 Transformer Engine: Lowers memory footprint per operation while maintaining accuracy, enabling bigger batches per GPU.
- NVLink + NVSwitch Topologies: Allow multi-GPU nodes to share batch workloads with minimal latency.
The result? Higher tokens/sec per GPU and predictable scaling across nodes — the foundation of high throughput batch inference.
Architecting for High-Throughput Batch Inference
Simply installing H200 GPUs won’t guarantee throughput. True performance comes from a bandwidth-first, architecture-first design:
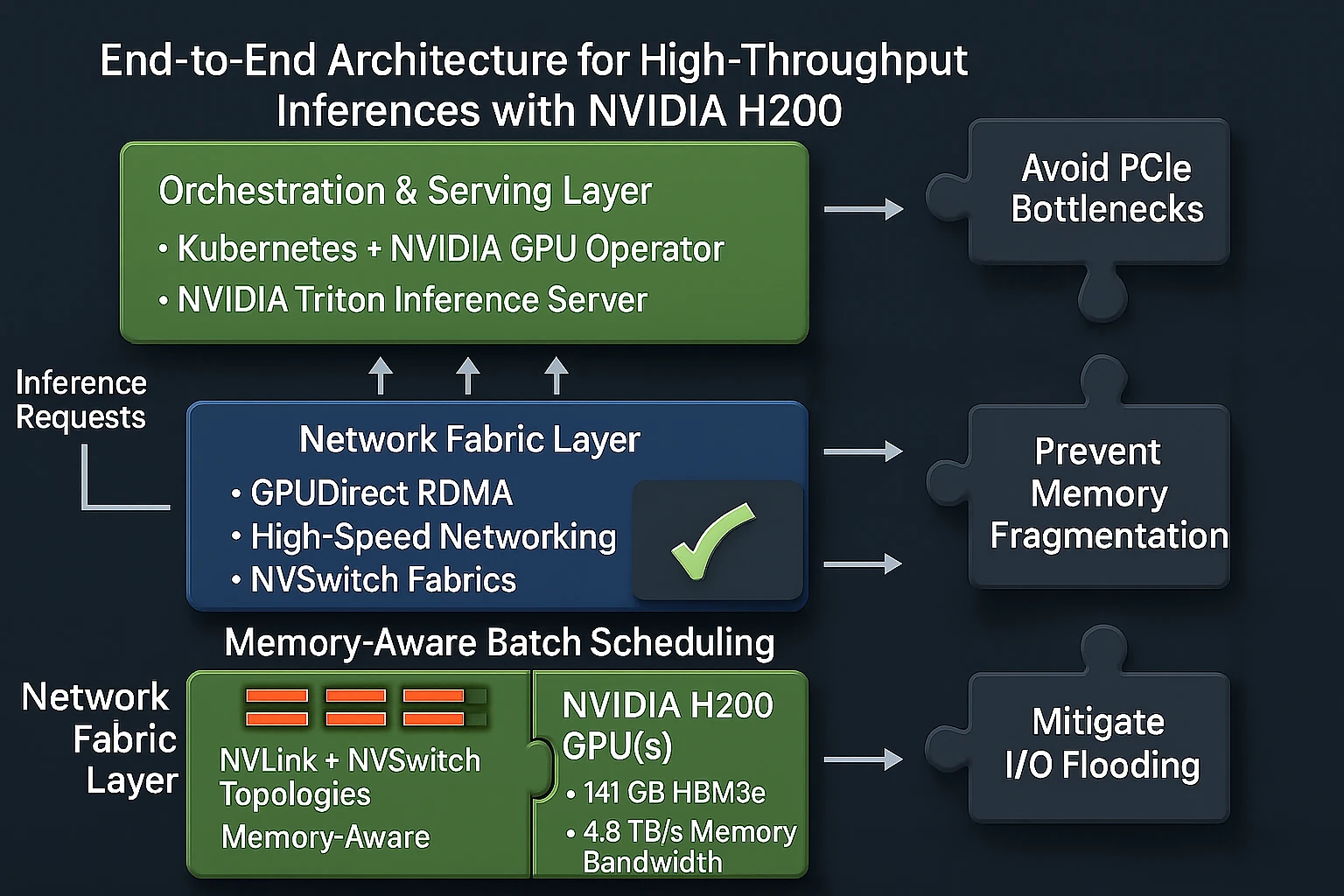
1. Memory-Aware Batch Scheduling
- Align batch size to HBM3e capacity.
- Pin memory-intensive jobs to specific GPUs to avoid fragmentation.
- Use NUMA-aware scheduling to minimize memory hops.
2. Network Fabric Optimization
- Deploy GPUDirect RDMA to eliminate CPU intermediaries during GPU-to-GPU transfers.
- Use InfiniBand NDR or 400 GbE networking to match GPU throughput.
- Design clusters with NVSwitch fabrics to prioritize intra-node traffic.
3. Orchestration and Automation
- Use Kubernetes + NVIDIA GPU Operator for flexible batch scheduling.
- Integrate NVIDIA Triton Inference Server for efficient multi-model serving.
- Implement autoscaling policies that adapt to workload bursts without idle GPU cycles.
Avoiding Common Pitfalls
Many enterprises fail to hit expected throughput, not because of GPU limitations, but because of architecture blind spots:
- PCIe Bottlenecks → Staging datasets through CPU RAM throttles GPU throughput.
- I/O Flooding During Checkpoints → Inference workloads stall when logging or storage spikes aren’t absorbed by burst buffers.
- Memory Fragmentation → Mixing small jobs with large LLM inference batches wastes HBM space.
- Outdated Software Stacks → Old CUDA/NCCL builds prevent H200 from unlocking FP8 and bandwidth optimizations.
- Cooling & Power Oversights → Sustained throughput collapses under thermal throttling if not designed for.
Maximizing ROI with High-Throughput H200 Clusters
For Managed Services Providers (MSPs) and enterprises alike, the ROI of H200 clusters depends on utilization discipline:
- Partition GPUs with MIG to support multi-tenant workloads.
- Tier workloads by latency/throughput needs (e.g., premium H200 tier vs. lower-cost legacy GPUs).
- Continuously benchmark throughput with real workloads, not synthetic tests.
- Use AI-driven schedulers to forecast and allocate GPU cycles to priority jobs.
Real-World Impact: Performance-to-Cost Gains
When architected correctly, H200 throughput yields massive improvements in both performance and cost efficiency:
| Metric | Legacy Cluster | H200-Optimized Cluster | Gain |
|---|---|---|---|
| Sustained GPU Utilization | ~60% | 93%+ | +33% |
| Tokens/sec (70B FP8 Model) | 210K | 380K | +81% |
| Cost per Inference Batch | 1.0x | 0.64x | -36% |
| Power Cost per 1K Tokens | 1.00x | 0.62x | -38% |
This means higher throughput per rack, fewer GPUs per workload, and longer hardware relevance before refresh cycles.
Semifly’s Role: From Spec Sheets to Real-World Throughput
At Semifly, we deliver more than hardware:
- Reference Architectures tailored for high-throughput batch inference.
- Pre-flight Validation to stress-test I/O, networking, and workload scheduling.
- Operational Playbooks for MSPs to maximize utilization and margins.
- Continuous Tuning Services to keep throughput at peak even as workloads evolve.
With our architecture-first approach, enterprises unlock the true throughput potential of NVIDIA H200 — turning specs into sustained, profitable performance.
Conclusion: The Throughput Era of AI
As AI adoption accelerates, the winners won’t be those with the biggest clusters — but those with the most efficient throughput per GPU.
The NVIDIA H200, with its unprecedented memory bandwidth and architectural optimizations, sets the new standard. But true success comes when it’s paired with the right provisioning strategy, orchestration stack, and operational discipline.
With Semifly as your partner, High Throughput Batch Inference isn’t just possible — it’s scalable, profitable, and future-proof.


More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now