Introduction: Why Components Define Success in AI
In the AI arms race, everyone talks about FLOPs, model parameters, and benchmark results. But behind every record-breaking training run or lightning-fast inference pipeline lies something more fundamental: components.
The NVIDIA DGX H200 is not just a server. It’s a carefully engineered convergence of GPUs, networking, memory, CPUs, storage, and power systems — each playing a specific role in turning raw compute into real-world AI throughput. For enterprises and managed services providers (MSPs), understanding the NVIDIA DGX H200 components is critical. It’s not enough to buy the hardware; the value lies in knowing how each part interacts, scales, and delivers business outcomes.
At Semifly, we help organizations transform this component-level design into bandwidth-first, utilization-maximized AI data centers. Let’s take a deep dive into the DGX H200’s architecture.
The Engine Room: H200 GPUs
The NVIDIA H200 GPU is the cornerstone of the DGX H200. Each GPU comes with:
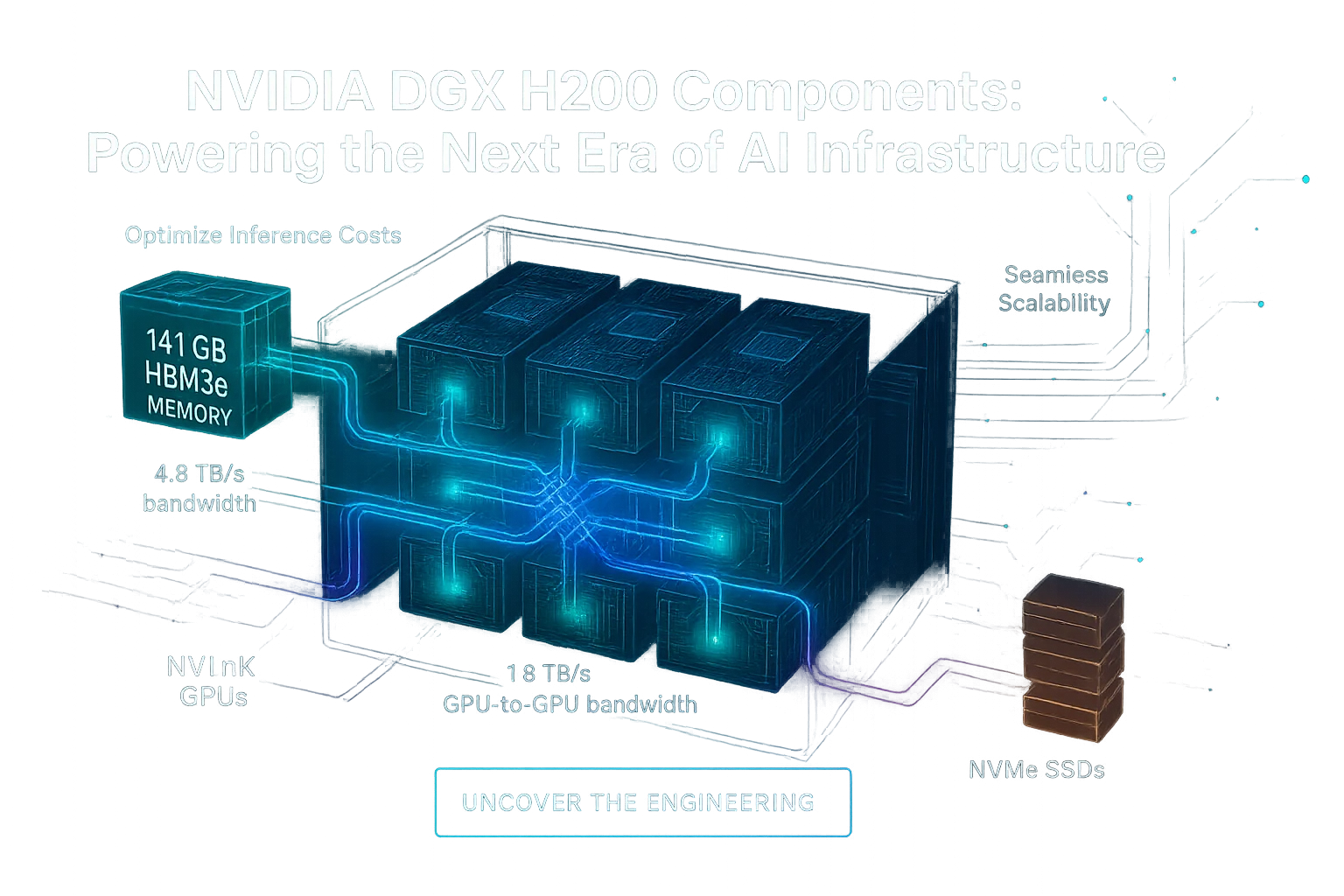
- 141 GB of HBM3e memory to hold large context windows and support multi-batch inference.
- 4.8 TB/s of memory bandwidth, ensuring Tensor Cores are never starved for data.
- Hopper architecture with FP8 Transformer Engine, lowering precision overhead while sustaining accuracy.

In the DGX H200 system, 8x H200 GPUs are interconnected with NVLink and NVSwitch, creating a single, high-bandwidth pool of compute. This configuration enables both large-model parallelism and multi-tenant inference serving with minimal latency.
The Nervous System: NVLink & NVSwitch
GPUs are only as fast as the links between them. DGX H200 incorporates:
- NVLink 4.0, delivering up to 1.8 TB/s GPU-to-GPU bandwidth.
- NVSwitch, enabling all-to-all connectivity across all eight GPUs.
This interconnect ensures that when enterprises train 70B+ parameter LLMs or run multi-modal AI workloads, they don’t hit bottlenecks inside the node. For HPC or AI inference, this means seamless scaling across GPUs, rather than wasting cycles waiting for data transfers.
The Orchestrator: CPUs and System Memory
Though GPUs drive throughput, CPU infrastructure remains essential for orchestration:
- High-core-count CPUs with PCIe Gen5 lanes handle I/O and control-plane tasks.
- NUMA-aware memory layouts minimize latency between system RAM and GPU workloads.
- Optimized schedulers keep memory-hungry jobs pinned close to the right GPU.
This balance allows the DGX H200 to run diverse workloads — from HPC simulations to multi-tenant inference — without choking at the CPU level.
Feeding the GPUs: Storage Subsystem
AI workloads are data-hungry, and storage must keep pace:
- NVMe SSDs with parallel file systems (BeeGFS, WekaIO, Lustre) sustain massive throughput.
- Burst buffers absorb spikes from checkpoints or logs during training.
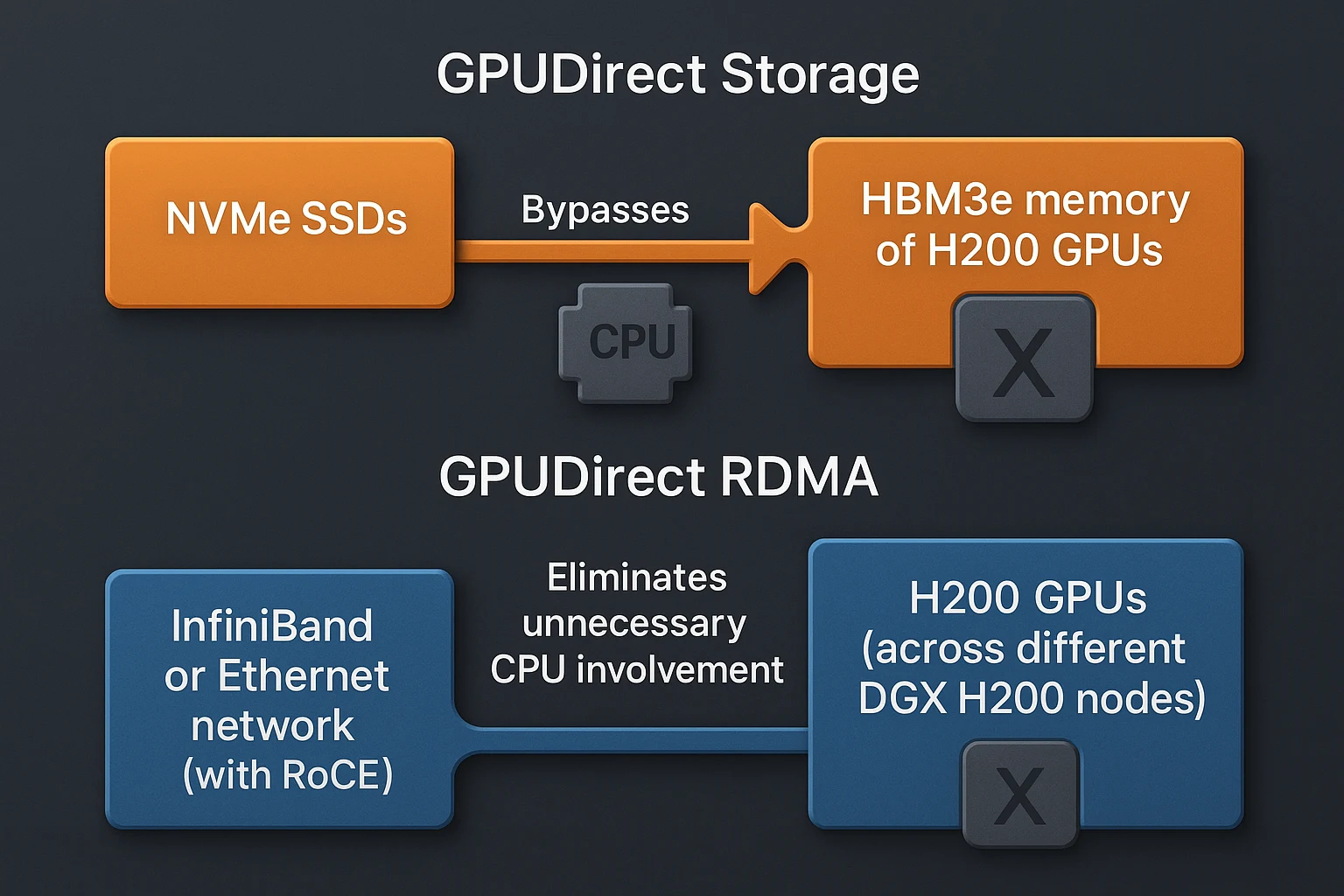
- GPUDirect Storage bypasses CPU overhead and moves data directly into GPU HBM.
For enterprises running inference pipelines, this ensures embeddings, context windows, and retrieval queries are always fed at GPU speed.
Scaling Beyond One Box: InfiniBand and Ethernet
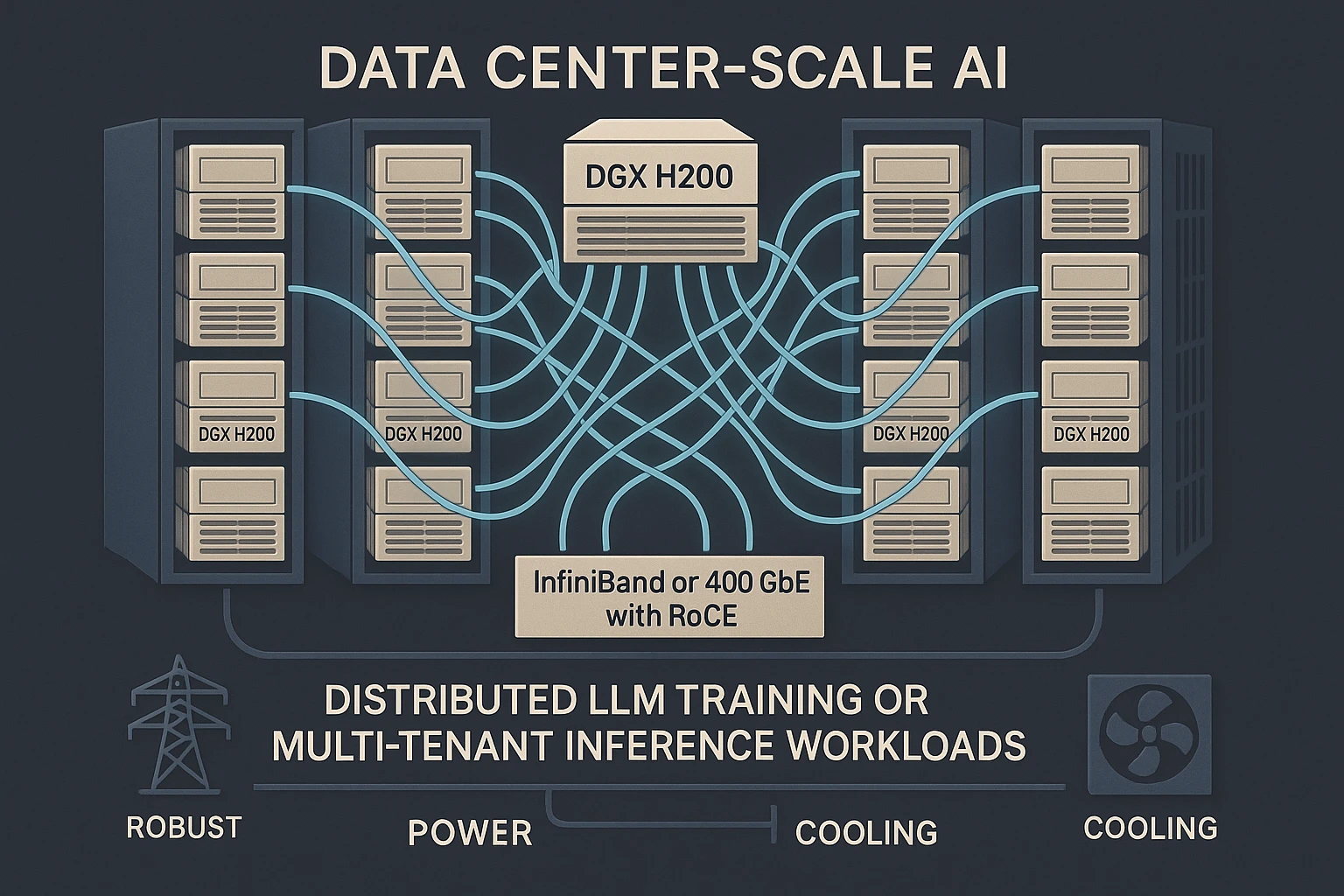
The DGX H200 is designed for data center-scale AI. To extend performance across racks:
- HDR/NDR InfiniBand and 400 GbE with RoCE enable low-latency GPU-to-GPU transfers.
- GPUDirect RDMA eliminates unnecessary CPU involvement in multi-node communication.
- Topologies such as fat-tree or Dragonfly+ ensure predictable performance at scale.
This networking layer is what enables DGX H200 clusters to power distributed LLM training or multi-tenant inference workloads across hundreds of nodes.
Sustaining Peak Loads: Cooling & Power Systems
The performance of eight H200 GPUs can’t be sustained without robust power and cooling:
- Redundant PSUs keep systems stable during workload spikes.
- Advanced cooling designs prevent thermal throttling under 24/7 AI workloads.
- Monitoring tools help IT teams proactively manage energy efficiency and uptime.
For enterprises, this translates into predictable operating costs — a key part of ROI.
Why Components Matter: From Specs to Outcomes
Each DGX H200 component directly contributes to measurable outcomes:
- GPUs + NVSwitch → Faster training convergence for LLMs.
- HBM3e + 4.8 TB/s bandwidth → Lower inference cost per token.
- Storage + GPUDirect → Reduced I/O stalls in high-throughput environments.
- Networking + RDMA → Seamless distributed scaling.
- Cooling + Power Systems → Reduced downtime and operational costs.
The takeaway? DGX H200 isn’t just hardware. It’s a carefully engineered balance of components designed for sustained AI throughput.
Semifly’s Approach: Beyond Components
At Semifly, we help clients bridge the gap between technical specs and operational success by:
- Delivering component-validated architectures for AI-first data centers.
- Running pre-flight stress tests across I/O, networking, and workloads.
- Offering managed services that handle lifecycle management, tuning, and orchestration.
- Providing continuous optimization with updated CUDA, NCCL, and MOFED stacks.
This ensures that every DGX H200 deployment pays for itself in higher utilization, faster training cycles, and lower cost-per-inference.
Conclusion: Building with the Right Components
The NVIDIA DGX H200 components are more than just parts in a server — they are the building blocks of next-generation AI infrastructure. With HBM3e memory, NVSwitch networking, parallel storage, and optimized cooling, the DGX H200 defines how enterprises can scale AI in 2025 and beyond.
And with Semifly as your partner, those components transform into business outcomes — not just speed, but efficiency, resilience, and profitability.










Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now