FEATURED STORY OF THE WEEK
NVIDIA B300 Software Stack: What You Need to Know

The NVIDIA B300 GPU, built on the Blackwell Ultra architecture, has generated significant excitement in the accelerated computing world, particularly among enterprises looking to scale Generative AI (GenAI) and complex reasoning workloads. If you have been tracking the rapid evolution of AI infrastructure, you know that the B300 represents a shift, moving away from general-purpose parallel processing to focus explicitly on the performance demands of the modern “AI factory”. However, this raw hardware power, boasting immense capacity like 288 GB of HBM3e memory per GPU, and a cutting-edge dual-die silicon design, cannot be fully realized without an equally evolved software foundation. The B300 Software Stack is precisely that foundation. It is a mandatory and cohesive layer of software engineered to manage the B300’s complexity, maximize its low-precision performance in formats like NVFP4, and smoothly enable hyperscale deployments. In this overview, we will comprehensively explore the three key layers of the B300 software ecosystem and understand how the software abstracts hardware features and transforms raw capacity into enterprise-ready performance.
The Foundational Infrastructure Layer and System Control
At the base of every accelerated computing platform lies its operating environment, the layer responsible for stability, security, and control. With the B300, this foundation matters even more because the hardware has been re-engineered for extreme throughput, multi-tenant use, and hyperscale deployment. The software must therefore provide predictable performance, fine-grained control, and easy operability across massive clusters. Image1_alt_text_ Three-layered diagram showing B300 software foundation: CUDA, specialized APIs, and AI orchestration. The foundational layer of the B300 software stack is built around three pillars: the operating environment, the GPU runtime, and the system management framework.

Operating Environment and GPU Runtime
The B300 runs on NVIDIA DGX OS, a performance-optimized Linux distribution tuned specifically for accelerated computing. For enterprises that standardize on existing datacenter environments, the stack also supports:
- Red Hat Enterprise Linux (RHEL)
- Rocky Linux
- Ubuntu
This flexibility ensures that B300 systems can be integrated cleanly into existing operational, security, and compliance frameworks. At the heart of the runtime is the NVIDIA CUDA platform, which provides the programming foundation for the B300’s Blackwell Ultra architecture. To execute the GPU’s latest capabilities including NVFP4 execution and updated Tensor Core instructions, the system requires:
- CUDA Toolkit 13.1 or later
- NVIDIA GPU Driver 590.44.01 or later
- Compute Capability 10.x and 12.x support
These versions introduce new optimizations and hardware paths that directly influence performance for LLMs, multimodal reasoning models, and large-scale inference.
System and Firmware Management
For a system designed to run dense, long-duration AI workloads, reliable out-of-band management is essential. The B300 includes a dedicated 1GbE RJ45 port connected to the Baseboard Management Controller (BMC), enabling administrators to monitor, configure, and control the system independent of the OS. Key capabilities include:
- Redfish API support for automated fleet-wide management.
- Real-time telemetry for power, thermals, and hardware health
- Remote configuration and diagnostics
- Lifecycle operations, including firmware updates and power sequencing
Security is reinforced through Secure Flash, which ensures that all firmware loaded onto the system is signed and authorized. Firmware updates are executed through:
- The nvfwupd CLI utility, or
- Redfish-based automation workflows
Some updates, particularly for BIOS and HGX tray components require a cold reboot, helping maintain consistency across multi-node environments.
Resource Allocation and System Control
Running AI at scale requires more than raw performance; it requires predictable scheduling and clean isolation. The foundational layer of the B300 stack enables:
- Precise GPU partitioning
- Low-overhead monitoring
- Stable multi-tenant operation
- Hardware-level protection and recovery
This systemic control ensures that the B300 performs reliably whether it’s part of a single-node development rack or a multi-thousand-GPU AI factory.
Core Programming Models and Specialized APIs
As GPU architectures evolve, developers face a growing challenge: how do you continue scaling performance without rewriting your code for every new generation of hardware? With the B300, this challenge becomes even more pronounced due to the dual-reticle design, expanded memory architecture, and new low-precision formats like NVFP4. To address this, the B300 software stack introduces updated programming models and specialized APIs that abstract hardware complexity while paving the way for new performance ceilings. This layer is where developers directly interact with the architecture and where NVIDIA has made some of the most significant changes since CUDA’s earliest days. The architectural complexity of the B300, particularly its dual-die design and sophisticated Tensor Cores, necessitates groundbreaking software abstraction. This layer provides the next generation of programming tools designed to maximize B300 performance and ensure that code remains portable across future architectural generations.
NVIDIA CUDA Tile: A New Way to Program Blackwell
CUDA Tile is the most significant update to the CUDA programming model in nearly two decades. It was created to bridge the gap between rchanging hardware and the need for stable, long-lasting code. Instead of relying on the traditional SIMT (Single Instruction, Multiple Thread) model where developers think in terms of warps, threads, and low-level scheduling, CUDA Tile allows them to write kernels in terms of logical “tiles” of data.
Why this matters
- It simplifies kernel development.
- It frees developers from hardware-specific tuning.
- It allows the compiler and runtime to choose the optimal execution path.
- It opens up new Tensor Core capabilities automatically.
CUDA Tile consists of two major components:
- CUDA Tile IR/; A new virtual instruction set architecture that abstracts tile-level operations from underlying GPU hardware. It ensures that kernels remain compatible even as Tensor Cores evolve from generation to generation.
- cuTile Python: A high-level, Python-based DSL for writing tile-oriented kernels. This makes low-precision AI kernel development far more accessible, especially for teams working on model optimization and inference workloads.
Blackwell-exclusive (for now)
CUDA Tile is initially available only on Blackwell products (Compute Capability 10.x and 12.x) reinforcing that it’s designed specifically to leverage B300’s next-generation Tensor Cores and NVFP4 acceleration paths. This model is especially impactful for:
- LLM inference
- Multimodal model pipelines
- Custom attention kernels
- Fine-grained tensor operations
- High-throughput, low-latency reasoning workloads
Advanced Resource Management APIs
Besides programming models, the B300 also introduces deeper control over how GPU resources are used, partitioned, and isolated. This is essential for multi-model serving, microservice pipelines, and enterprise-grade multi-tenancy. Two capabilities stand out:
MLOPart (Memory Locality Optimization Partitioning)
B300 GPUs use a dual-reticle design, essentially two silicon dies stitched together. To reduce the latency overhead of cross-die memory access, MLOPart allows the GPU to be presented as two virtual CUDA devices, with memory locality preserved as much as possible.
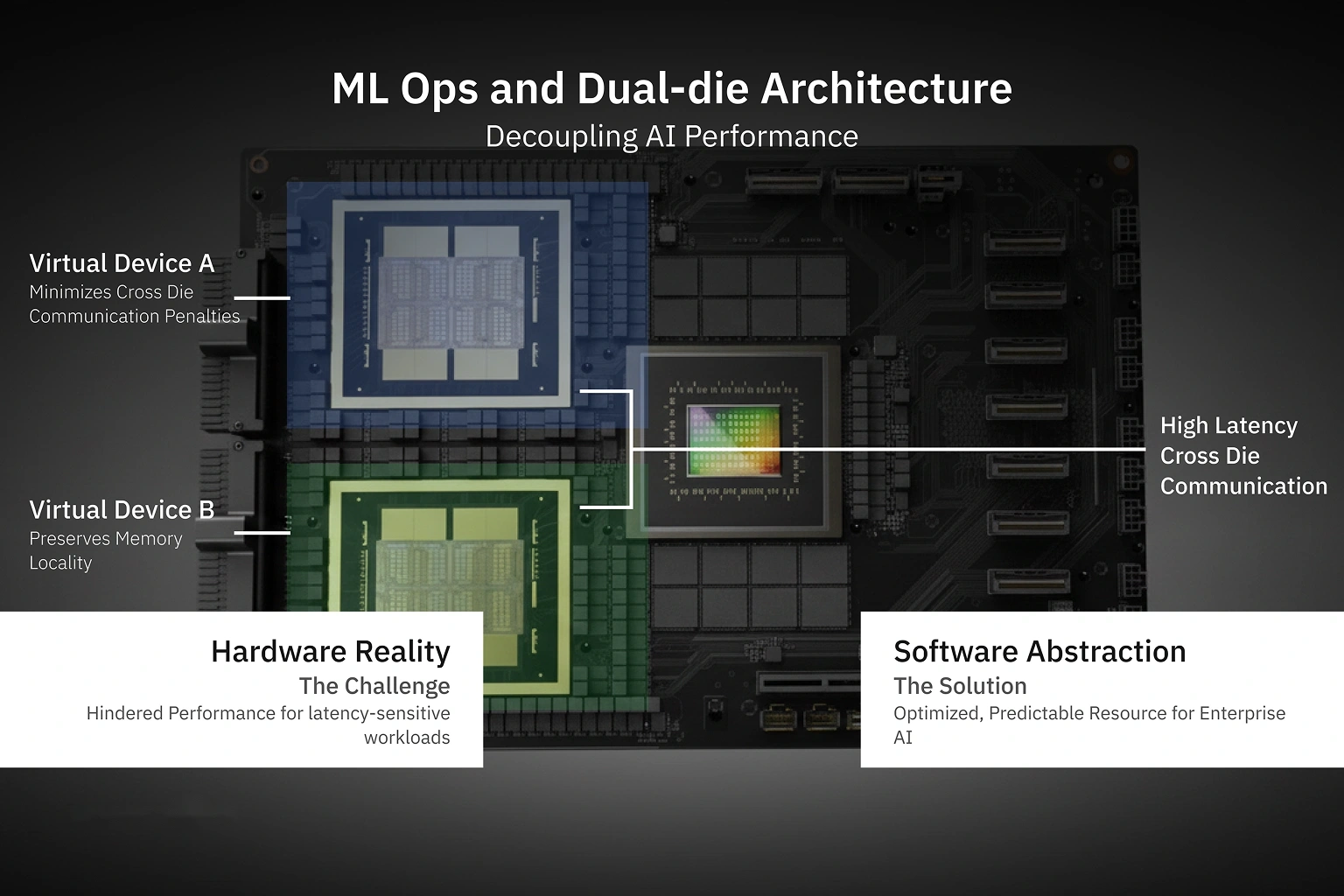
Benefits of MLOPart:
- Minimizes cross-die communication penalties
- Improves latency for inference and microservices
- Enables better packing of smaller models
- Supports multi-pipeline and multi-user environments
This is especially helpful when serving many smaller workloads instead of one massive monolithic model.
Static SM Partitioning
Where MLOPart focuses on memory locality, Static SM Partitioning focuses on compute isolation. It divides Streaming Multiprocessors (SMs) into fixed, exclusive partitions, each reserved for a specific client or workload. This differs from dynamic MPS (Multi-Process Service):
- Static SM partitions are predictable
- They ensure consistent performance for each tenant
- They prevent workloads from interfering with one another
- They enable regulated or latency-sensitive operations
Together, these innovations make the B300 not just powerful, but usable, future-proof, and highly efficient in real-world AI factory environments.
Accelerated AI Frameworks and Orchestration
With the foundational layers and programming models in place, the next part of the B300 software stack focuses on what enterprises actually need to run at scale: optimized AI frameworks and orchestration tools. This is where the B300 transitions from hardware to a full production-grade AI platform. This layer provides the performance acceleration, low-precision execution, serving infrastructure, and cluster-level management required to operate large-scale GenAI workloads efficiently.
Native AI Framework Acceleration
The Blackwell Ultra architecture is fundamentally optimized for Generative AI, delivering a 1.5x boost in dense FP4 performance and a 2x boost in attention performance over previous generations. These gains are realized through software that natively supports low-precision formats:
- NVFP4 Optimization: The software stack includes optimized kernels designed to leverage the breakthrough NVFP4 precision format for large-scale reasoning tasks.
- Inference Engines: Native support is provided for key LLM inference and reasoning frameworks, including TensorRT-LLM (optimized for B300’s architecture and NVFP4), as well as SGLang and vLLM (designed for high-throughput, low-latency LLM serving).
Enterprise Management and Orchestration
To operate high-density B300 hardware efficiently as an AI factory, enterprises rely on a full software suite:
- NVIDIA AI Enterprise (NVAIE): This commercial software suite provides a production-grade, secure foundation, including essential tools, optimized frameworks, and over 100 pretrained models,. It includes NVIDIA NIM microservices for standardized, containerized deployment and scaling of foundational models.
- NVIDIA Mission Control: Integrating NVIDIA Run:ai technology, Mission Control manages AI data center operations, specifically handling orchestration and job scheduling across massive DGX clusters. This is critical for maximizing GPU efficiency in multi-tenant environments.
- High-Performance Serving: NVIDIA Triton Inference Server is the recommended open-source solution for deploying models in production. Triton works in synergy with TensorRT, utilizing dynamic scheduling and concurrent model execution to maximize B300 throughput for real-time inference workloads.
Strategic Imperative
The B300 hardware de-emphasizes high-precision computing, with FP64 performance deliberately reduced to approximately 1.2 TFLOPS (compared to ~67 TFLOPS on Hopper). This strategic choice reinforces that the B300 is optimized purely for low-precision AI and LLM workloads. The successful adoption of B300 is entirely dependent on adopting the full software stack described here. Ignoring this ecosystem means missing the generational performance gains and utilizing hardware that is strategically unsuitable for traditional scientific HPC workloads. The B300 Software Stack acts as the specialized interpreter that converts the language of Blackwell Ultra hardware into the high-performance throughput required by the age of AI reasoning. Organizations that embrace this full-stack approach are positioned to realize the massive potential of the AI factory.
Accessing the B300 Through the Semifly Marketplace
As organizations prepare to operationalize the B300 platform and its highly specialized software stack, the next step is acquiring hardware and validated components through a reliable channel. The Semifly Marketplace offers a streamlined path to begin that journey:
- Purchase Verified B300 Systems: Access NVIDIA DGX B300 configurations, networking components, and compatible software bundles that are pre-validated for scale-out AI workloads.
- Simplified Procurement for AI Factories: The marketplace provides transparent, enterprise-grade configurations designed to match the B300’s software-driven performance model, ensuring every component aligns with real-world GenAI deployment needs.
- Architecture and Deployment Guidance: Semifly’s solution specialists assist with system design, cluster topology, networking choices, and software stack alignment, helping teams avoid misconfiguration and bottlenecks.
- Integration With Existing Infrastructure: Whether expanding a current GPU cluster or building a new AI facility, the marketplace helps you identify exactly what you need to integrate the B300’s full stack into your environment.
If you need expert assistance before purchasing, you can schedule a free consultation call with Semifly to evaluate your architecture and plan deployment strategy with confidence.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now