Large Language Models (LLMs) like ChatGPT or Llama are AI systems that understand and generate human-like text. Training them is incredibly demanding. Why? Because they learn from massive amounts of text data and have billions, even trillions, of internal settings called “parameters.” Adjusting all these parameters requires immense mathematical calculations. Doing this on ordinary computers would take years or even centuries.
This is where GPU clusters become essential. A GPU (Graphics Processing Unit) is a specialized chip, originally for graphics, but perfect for the math in AI. Unlike a regular computer chip (CPU), a GPU can do thousands of calculations simultaneously. A “GPU cluster” is a network connecting many of these powerful GPUs together.
This allows the huge task of training LLMs on GPU clusters to be split up and processed in parallel across many chips. This parallel processing drastically cuts down training time from years to weeks or days. Without GPU clusters, training modern LLMs at scale simply wouldn’t be practical. For enterprises, this setup is now non-negotiable to compete in AI.
A key player boosting this efficiency is NVIDIA’s new H200 GPU. This hardware brings significant upgrades in memory speed and capacity. Think of GPU memory (VRAM) like the workspace a chip has. Larger, faster workspace means the GPU can handle bigger chunks of data at once during training.
The H200 promises to make training LLMs on GPU clusters faster and more efficient than ever before, tackling the massive computational load more effectively. Early reports suggest it could be a game-changer for speed and cost.
The purpose of this blog is straightforward. We will explore the real-world challenges companies face when training LLMs on GPU clusters. We’ll look at common problems like running out of GPU memory, network bottlenecks slowing things down, and managing complex software across hundreds of chips.
Crucially, we’ll also outline proven solutions and best practices. These include specific techniques, software tools, and hardware strategies that help enterprises successfully train powerful LLMs on these large-scale systems. Our goal is to provide a practical guide based on current technology and expert knowledge.
1. Why Are GPU Clusters the Backbone of LLM Training?
Training modern Large Language Models (LLMs) is one of the most computationally intensive tasks in AI. What makes GPU clusters absolutely essential? Let’s break down the key reasons.
Compute Demands of LLMs
LLMs like GPT-4 or Llama 2 are enormous. They often have billions or even trillions of internal settings called “parameters.” Adjusting these parameters requires processing massive datasets. This demands incredible amounts of mathematical calculations. Doing this on standard computers would take years. The energy required would also be impractical. GPU clusters provide the necessary raw power and efficiency.
GPU Advantages
A GPU (Graphics Processing Unit) is fundamentally different from a regular computer processor (CPU). GPUs have thousands of tiny cores (like NVIDIA’s CUDA cores) designed to handle many simple calculations at the exact same time. This parallel architecture is perfect for the core math in LLM training, which involves massive matrix multiplications. CPUs, built for general tasks, are much slower at this specific type of workload. GPUs are simply optimized for the heavy lifting AI requires.
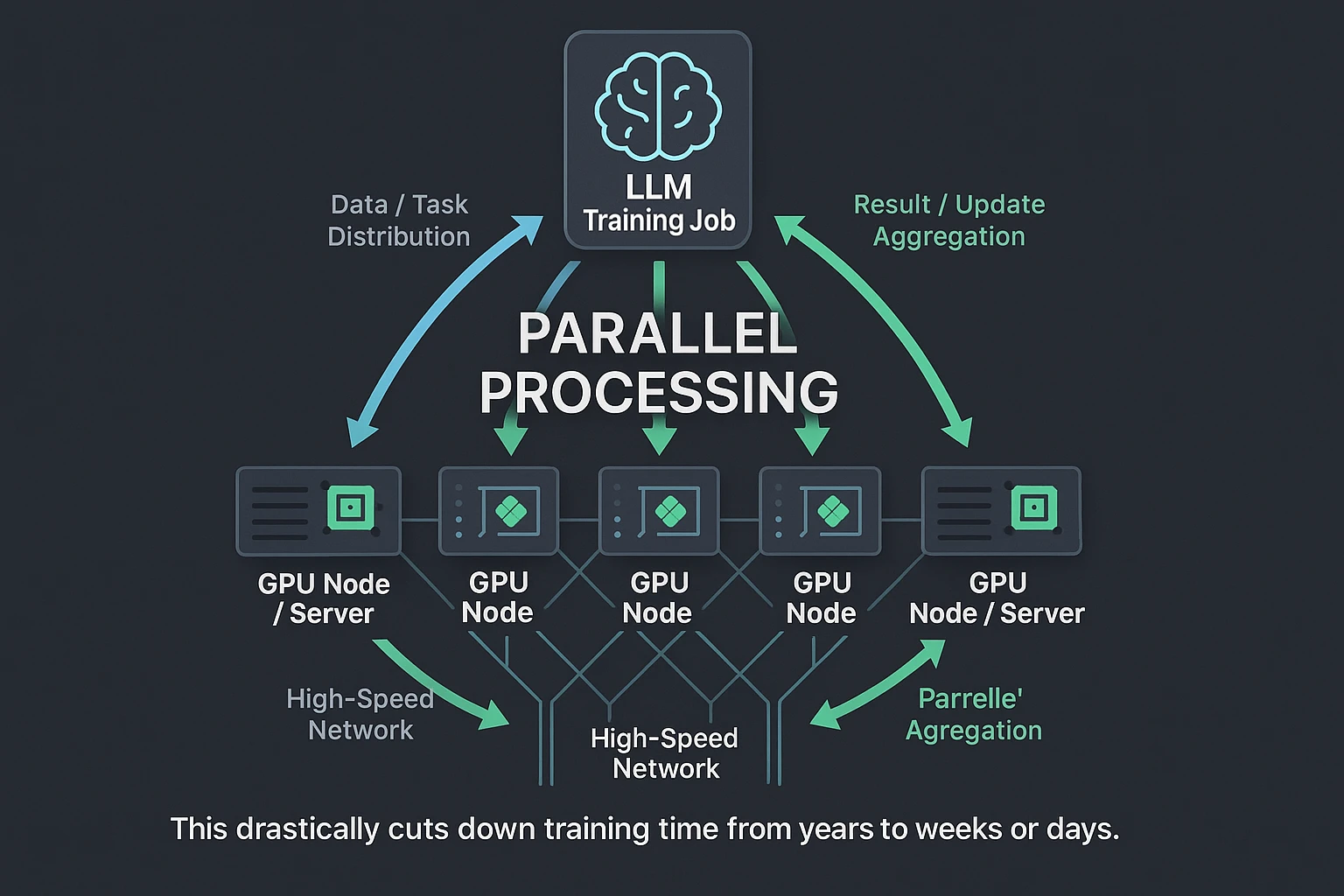
Cluster Scaling
A single GPU, while powerful, isn’t enough for giant LLMs. This is where clusters come in. A GPU cluster connects many individual GPU servers (nodes) via high-speed networks. Training LLMs on GPU clusters works by splitting the enormous workload across hundreds or thousands of these GPUs. They work in parallel, each handling a portion of the data or the model. This horizontal scaling turns training times that might take months on a single machine into a matter of days or weeks. Without clusters, training cutting-edge models isn’t feasible.
Real-World Impact
Leading LLMs explicitly rely on massive GPU clusters. For example, models like OpenAI’s GPT-4 and Meta’s Llama 2 were trained on clusters containing thousands of GPUs working together. These clusters aren’t a luxury; they are the fundamental infrastructure enabling the development of state-of-the-art AI.
The scale and speed provided by clusters are directly responsible for the capabilities we see in these advanced models today. Enterprises aiming to build competitive LLMs must adopt this approach.
The NVIDIA H200 GPU is a major leap forward for AI training. It directly tackles the biggest bottlenecks in training LLMs on GPU clusters. Let’s see how its new features make a real difference.
HBM3e Memory: Bigger Batches, Faster Access
The H200 uses cutting-edge HBM3e memory. Think of this as the GPU’s ultra-fast workspace. It offers a massive 141 GB per second bandwidth – much faster than the H100’s 80 GB/s. This speed boost means the H200 can load training data much quicker.
More importantly, it can handle significantly larger “batches” of data during training. Bigger batches mean the model learns more efficiently each time the GPUs calculate updates, speeding up overall progress.
FP8 Precision: Faster Math, Less Memory
The H200 introduces strong support for FP8 precision. FP8 stands for “8-bit floating point,” a way of representing numbers that uses less space than older formats like FP16 (16-bit). Using FP8 cuts the memory needed for calculations roughly in half.
This lets the GPU process twice as much data in the same time. It also reduces the strain on the GPU’s memory. For training LLMs on GPU clusters, this translates to faster training cycles and the ability to train larger models without running out of memory.
NVLink 4.0: Super-Fast GPU Communication
When training LLMs on GPU clusters, GPUs constantly share information. Slow communication creates bottlenecks. The H200 features NVLink 4.0, a super-fast connection between GPUs.
With a speed of 900 GB per second, it’s far quicker than previous versions. This minimizes delays when GPUs exchange data during training. Faster communication keeps all GPUs in the cluster busy working, not waiting, leading to much higher overall efficiency.

Cluster Integration: Built for Scale
The H200 is designed to work seamlessly in large clusters. It fits into HGX H200 systems, which pack 4 or 8 H200 GPUs into a single server node. This dense packing provides enormous computing power per physical machine. High-density nodes simplify building and managing massive clusters needed for the largest LLMs, making the infrastructure more efficient.
Energy Efficiency: Doing More with Less Power
Training massive LLMs consumes huge amounts of electricity. The H200 is designed for better performance per watt. It delivers up to much higher more performance per watt than the H100 for certain LLM tasks. This means enterprises can train models faster or train larger models without a proportional surge in energy costs. This significantly lowers the total cost of operation for training LLMs on GPU clusters.
Enterprise Impact: Speed and Savings
The combined effect of the H200’s features is transformative for businesses. Faster training means quicker experimentation and model iteration – getting valuable AI applications to market sooner. Reduced memory needs and lower energy consumption directly translate to lower cloud computing bills. Optimizing hardware efficiency like this is critical for enterprises managing the high costs of large-scale AI projects.
3. What Are the Biggest Challenges in GPU Cluster LLM Training?
Training LLMs on GPU clusters unlocks immense power, but it also introduces significant hurdles. Scaling across hundreds or thousands of GPUs magnifies specific technical problems that must be managed. Here are the most common and impactful challenges.
Memory Bottlenecks
The biggest strain comes from storing “activations” (temporary data from each layer during processing) and “gradients” (signals used to adjust the model). These can consume a significant part of GPU’s dedicated memory. This leaves little room for the model parameters and the data batch being processed. Running out of VRAM causes crashes or forces the use of impractically small data batches, drastically slowing down training LLMs on GPU clusters.
Network Latency
In a cluster, GPUs constantly share data, especially during steps like AllReduce (a synchronization step where GPUs combine their calculated gradients). If the network links between servers (nodes) are slow or congested, GPUs spend valuable time waiting for data instead of calculating. This idle time, known as network latency, can drastically reduce the overall efficiency of the cluster, sometimes leaving GPUs utilized less than 50% of the time.
Hardware Failures
Operating a vast cluster with thousands of GPUs increases the chance of hardware problems. A single failing GPU, network card, power supply, or even a cooling fan in one server node can halt the entire training job. Given that training runs often last for weeks, the risk of a failure causing days or weeks of lost progress and compute resources is a major operational headache for large-scale training LLMs on GPU clusters.
Software Complexity
Coordinating the training workload across so many GPUs is incredibly complex. Engineers must choose and implement strategies like data parallelism (splitting data batches), model parallelism (splitting the model layers), or a hybrid approach.
Configuring this distributed training software correctly, debugging issues across many machines, and ensuring efficient communication requires deep expertise and adds significant overhead to the development process.
Table: Key Challenges and Mitigation Strategies
| Challenge |
Impact |
Solution Example |
| VRAM Exhaustion |
OOM crashes, small batch sizes |
Gradient checkpointing, FP8 quantization |
| Network Congestion |
Low GPU utilization |
NVLink topology, overlapping compute/comm |
| Hardware Fragility |
Job failures after days/weeks |
Checkpointing, fault-tolerant frameworks |
| Parallelism Overhead |
Complex code, debugging hurdles |
Automated tools (e.g., Alpa) |
4. How Can You Scale LLM Training Across Massive GPU Clusters?
Successfully training LLMs on GPU clusters with thousands of chips requires smart strategies to split the work efficiently. Overcoming bottlenecks like memory limits and slow communication is key. Here are the main approaches and tools used.
Parallelism Strategies: Splitting the Work
The core idea is to divide the huge model and data across many GPUs. Data parallelism gives each GPU a copy of the entire model but a different slice (shard) of the training data batch. They work independently and then sync their updates. This is common and relatively simple, often implemented with tools like PyTorch DDP.
Model Parallelism: Handling Giant Models
When a single model is too big for one GPU’s memory, you split the model itself. Tensor parallelism splits individual layers (like the giant matrices inside an attention layer) across multiple GPUs. Pipeline parallelism splits the model vertically, assigning different groups of layers to different GPUs. Data flows through these stages like an assembly line. Both are essential for models with billions of parameters.
3D Hybrid Parallelism: The Ultimate Scalability
For the largest models (like trillion-parameter LLMs), combining techniques is essential. 3D hybrid parallelism integrates data, tensor, and pipeline parallelism simultaneously. Frameworks like NVIDIA’s Megatron-LM automate this complex orchestration. This allows training LLMs on GPU clusters at an unprecedented scale, efficiently utilizing every GPU.
Frameworks and Tools: Automation is Key
Manually managing parallelism across thousands of GPUs is impractical. Tools like Alpa (built on Ray) automatically analyze the model and cluster and choose the best parallelism strategy, significantly simplifying the process for engineers. Frameworks like Megatron-DeepSpeed provide highly optimized code, especially for communication between GPUs, reducing overhead and speeding up training.
Cluster Optimization: Squeezing Out Performance
Beyond parallelism, fine-tuning the cluster setup boosts efficiency. Topology-aware scheduling ensures GPUs that need to communicate intensely (like those sharing tensor-parallel layers) are placed on servers with the fastest connections (like NVLink), minimizing slow network hops.
Using compilation (like CUDA graphs) converts the training steps from flexible Python code into a rigid, pre-optimized sequence the GPU executes directly. This drastically cuts down on small delays caused by the Python interpreter, improving overall speed.
Table: Scaling Techniques for Large Clusters
| Technique |
Use Case |
Benefit |
| Pipeline Parallelism |
100B+ parameter models |
Minimizes GPU idle time |
| Tensor Parallelism |
Large layers (e.g., 40B params) |
Splits single layers across GPUs |
| Overlapped Communication |
Bandwidth-bound workloads |
Hides latency (compute/comm overlap) |
| Ray Clusters |
Dynamic resource management |
Auto-scaling, fault recovery |
5. What Best Practices Ensure Enterprise Success?
Successfully training LLMs on GPU clusters in an enterprise setting goes beyond raw compute power. Strategic planning across infrastructure, cost, security, and talent is essential. Implementing these best practices maximizes return on investment and minimizes risks.
Infrastructure Design: Choosing the Right Foundation
Enterprises must decide between cloud platforms (like AWS or Azure) for flexibility and on-premises solutions (like NVIDIA DGX/HGX systems) for control. A hybrid approach is common.
Equally critical is high-performance storage. Training requires feeding massive datasets to GPUs rapidly. Parallel file systems like Lustre FS provide the necessary throughput, preventing data loading from becoming a bottleneck during training LLMs on GPU clusters.

Cost Optimization: Managing the Investment
Cloud costs can escalate quickly. Using spot instances (discounted, interruptible cloud VMs) for resilient parts of the workload offers significant savings. Techniques like fractional GPU sharing allow multiple smaller jobs to run efficiently on a single GPU.
Continuous monitoring of GPU utilization metrics is vital. This data helps right-size clusters, avoiding costly under-utilization (idle resources) or under-provisioning (delays from insufficient resources).
Security and Compliance: Protecting Assets
Sensitive training data and valuable models require robust protection. Implement data isolation using private network subnets within the cloud or on-prem cluster. Encrypt both the data at rest and the final trained models. These measures are non-negotiable for meeting regulatory standards and safeguarding intellectual property during training LLMs on GPU clusters.
Team Skills: The Human Element
The complexity demands specialized expertise. MLOps engineers are crucial for managing the training pipeline, infrastructure, and deployment. Deep knowledge of distributed systems is essential to configure, optimize, and troubleshoot the large-scale parallelism and communication inherent in training LLMs on GPU clusters. Investing in or acquiring this talent is fundamental.
Conclusion
Training LLMs on GPU clusters is the essential foundation for developing powerful large language models. While extremely demanding, clusters – especially those powered by advanced hardware like the NVIDIA H200 – make this ambitious task achievable. However, success requires careful planning and execution, not just raw computing power.
The journey involves navigating significant hurdles. Memory limits, network bottlenecks, hardware fragility, and software complexity are major challenges when training LLMs on GPU clusters. Overcoming these requires smart strategies. Key takeaways include finding the right balance between data, tensor, and pipeline parallelism techniques, using automation tools like Alpa or Megatron-DeepSpeed to manage complexity, and designing the cluster network topology to minimize communication delays.
Looking ahead, the field continues to evolve rapidly. Next-generation GPUs, such as NVIDIA’s Blackwell architecture, promise even greater efficiency and scale for training LLMs on GPU clusters. While still emerging, technologies like quantum computing may one day offer new paradigms.
Most importantly, ongoing hardware and software advancements aim to democratize access, gradually lowering the cost barrier for enterprises to participate in cutting-edge AI development. Strategic adoption of clusters remains vital for harnessing the power of LLMs.











Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now