FEATURED STORY OF THE WEEK
NVIDIA H200 vs H100: What CIOs Must Know Before Signing the Next GPU Contract

GPUs are no longer just infrastructure—they’re strategic assets. As enterprises rush to scale AI, the choice between NVIDIA’s H100 and its new successor, the H200, is shaping up to be a defining one.
The H100 has proven its worth since 2022, powering everything from LLMs to HPC. But the H200 raises the bar with faster memory and better efficiency. It’s designed for scale—but at a higher price point.
This blog breaks down the trade-offs: performance, availability, energy savings, and long-term value. For CIOs, choosing the right GPU isn’t just a technical decision—it’s a competitive one.
1. Head-to-Head Specifications
Architecture
Both the H100 and H200 are built on NVIDIA’s Hopper architecture—tailored for AI workloads. But the H200 brings a crucial edge: HBM3e memory. It’s faster, more efficient, and removes bottlenecks the H100 still contends with.
Power Consumption
On paper, both GPUs run at ~700W TDP. In practice, the H200 squeezes more value out of every watt, thanks to architectural tweaks and its upgraded memory stack.
Why It Matters
HBM3e doesn’t just move data faster—it uses less energy to do it. That means more throughput with no added power draw. It’s an invisible gain, but one that shows up on your power bill.
Cooling + Cost Implications
Both cards demand robust cooling. But with the H200’s efficiency, there’s slightly less waste heat to manage. In dense deployments, that could mean 5% lower cooling costs—a small number with big scale impact.
For enterprises running racks of GPUs 24/7, efficiency isn’t just a bonus. It’s a budget line.
2. Performance Metrics
Memory: Speed and Scale
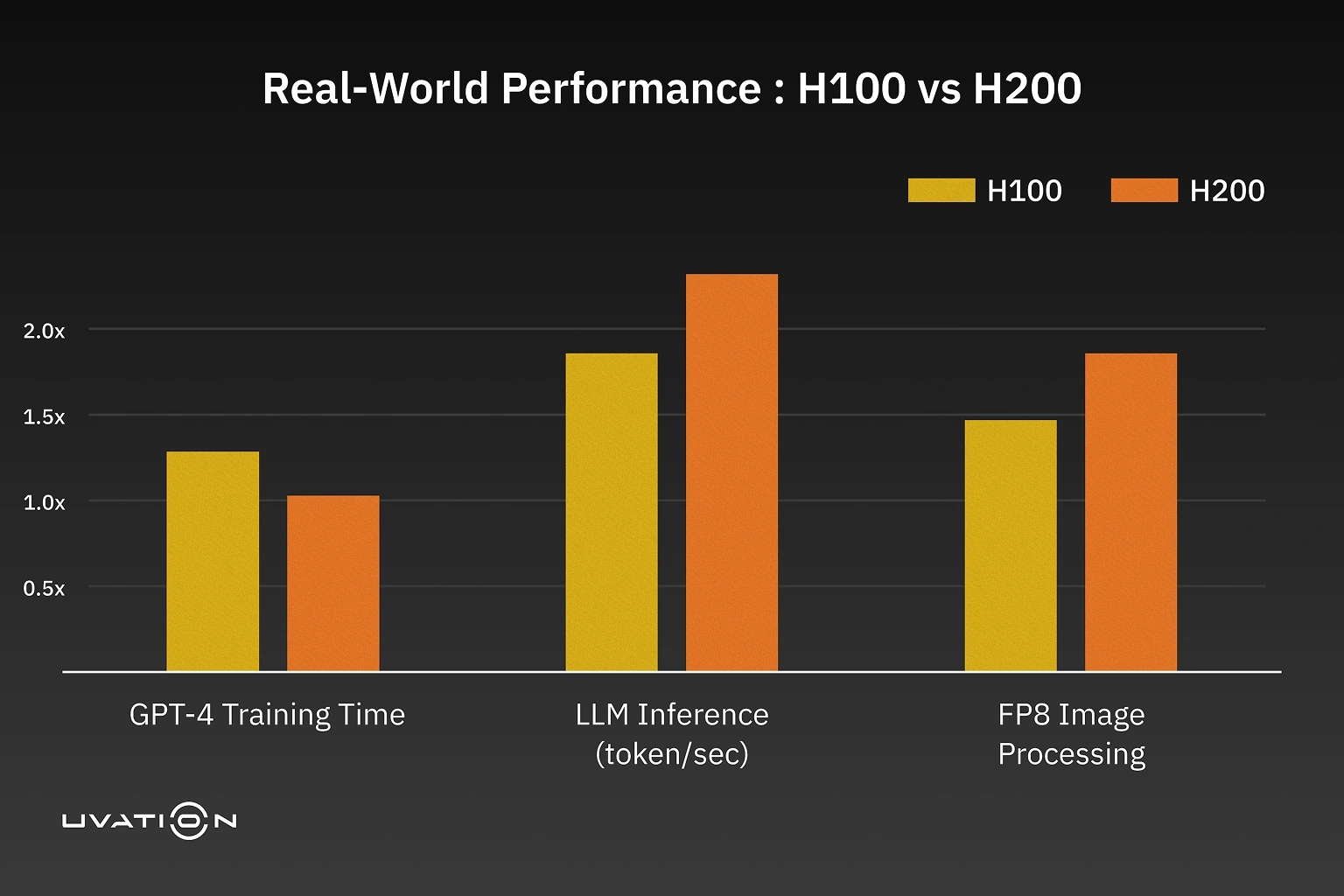
The H200 ships with 141GB of HBM3e memory—nearly double the H100’s 80GB. But it’s not just about size. With 4.8 TB/s bandwidth, the H200 moves data 43% faster. That matters when you’re training models north of 100 billion parameters. What struggles to fit on the H100 runs natively on the H200—no sharding, no hacks.
Inference and Training Gains
In practical terms, the H200 delivers up to 2x faster inference. That means real-time responses, lower latency, and smoother user experiences. Training sees a ~20% speed boost—cutting cloud hours and speeding time-to-market.
FP8 / FP16 Efficiency
Lower-precision math is common in vision, voice, and inferencing tasks. The H200 is optimized here, running FP8 and FP16 workloads faster and with lower power draw. Processing 10,000 images? The H200 will likely do it in half the time, using less energy.
Bottom Line
The H200 isn’t just faster. It changes the economics of AI. Quicker inference means happier users. Bigger memory means fewer compromises. Smarter precision math means lower bills.
Software Compatibility
Both GPUs run on CUDA 12+, so existing stacks (PyTorch, TensorFlow) work out of the box. No major refactoring needed. But to unlock full H200 gains—especially memory speed—you’ll want to update libraries and tweak configs. Think of it like swapping in a new engine but tuning it for track performance.
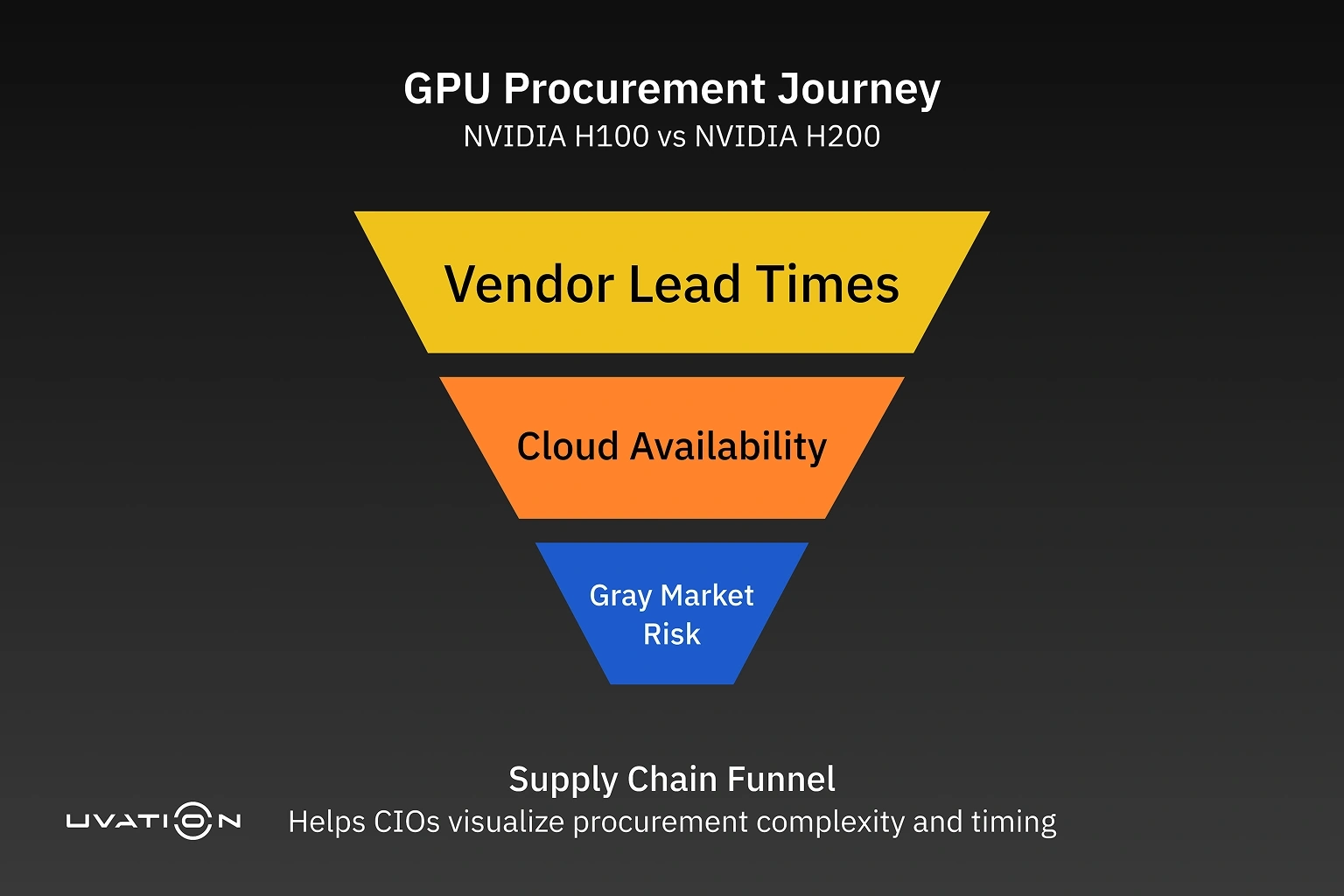
3. Availability and Supply Chain Considerations
H100: Still in High Demand
Launched in 2022, the H100 remains the gold standard—but getting one isn’t easy. Lead times stretch 3–6 months, and volume buyers like AWS and Google dominate supply.
If you’re a startup or mid-market enterprise, prepare for delays—or higher prices on secondary markets. Renting cloud instances helps, but costs add up fast.
Supply Chain Pressures
Hopper-based chips are built on 4nm wafers from TSMC, and capacity is tight. Automotive, cloud, and AI workloads are all in line. Add export controls and geopolitical friction, and the result is a fragmented, unpredictable market.
H200: Promising, But Not Plug-and-Play
NVIDIA is prioritizing hyperscalers and top OEMs for early H200 shipments. That means longer wait times for most buyers—just like the H100 rollout.
And there’s a bottleneck: HBM3e. SK Hynix is scaling up, but demand is rising faster than supply. For now, expect limited availability and allocation-based purchasing.
What This Means for CIOs
If you need GPUs in the next 3–6 months, the H100 is your realistic option. For 2025 deployments and beyond, pre-book H200s early. The sooner you’re in the queue, the better your odds.
4. Strategic Procurement Tips for CIOs
1. Match Lead Times to Roadmaps
If your AI rollout is slated for 2025, the H100 is the safer bet—it’s available (with some patience) and battle-tested. Waiting on the H200 could mean project delays and missed milestones.
But if you’re planning for 2026 and beyond, lock in H200 orders now. Early commitments to vendors like Semifly can get you priority access.
2. Strengthen Vendor Relationships
Partner closely with OEMs like Dell, HPE, or Lenovo. Those relationships open doors—whether to reserved GPU inventory or preferred pricing. The same goes for cloud partners offering GPU-backed reserved instances.
3. Diversify Deployment
Blend on-prem H100 clusters with cloud-based H200 instances. That hybrid model gives you control today and flexibility tomorrow—without overcommitting on a single architecture.
4. Negotiate with Leverage
Use multi-year GPU contracts to secure pricing and delivery windows. NVIDIA’s Enterprise License Agreements offer volume discounts—but you’ll need to stay flexible on timelines.
5. Watch the Gray Market (With Caution)
Third-party sellers can bridge short-term gaps, but the risks are real: no warranty, firmware tampering, and compliance headaches. If you go this route, stick to verified partners in NVIDIA’s official network.
5. Cost Analysis: H200 Price vs H100 Value
Upfront Costs
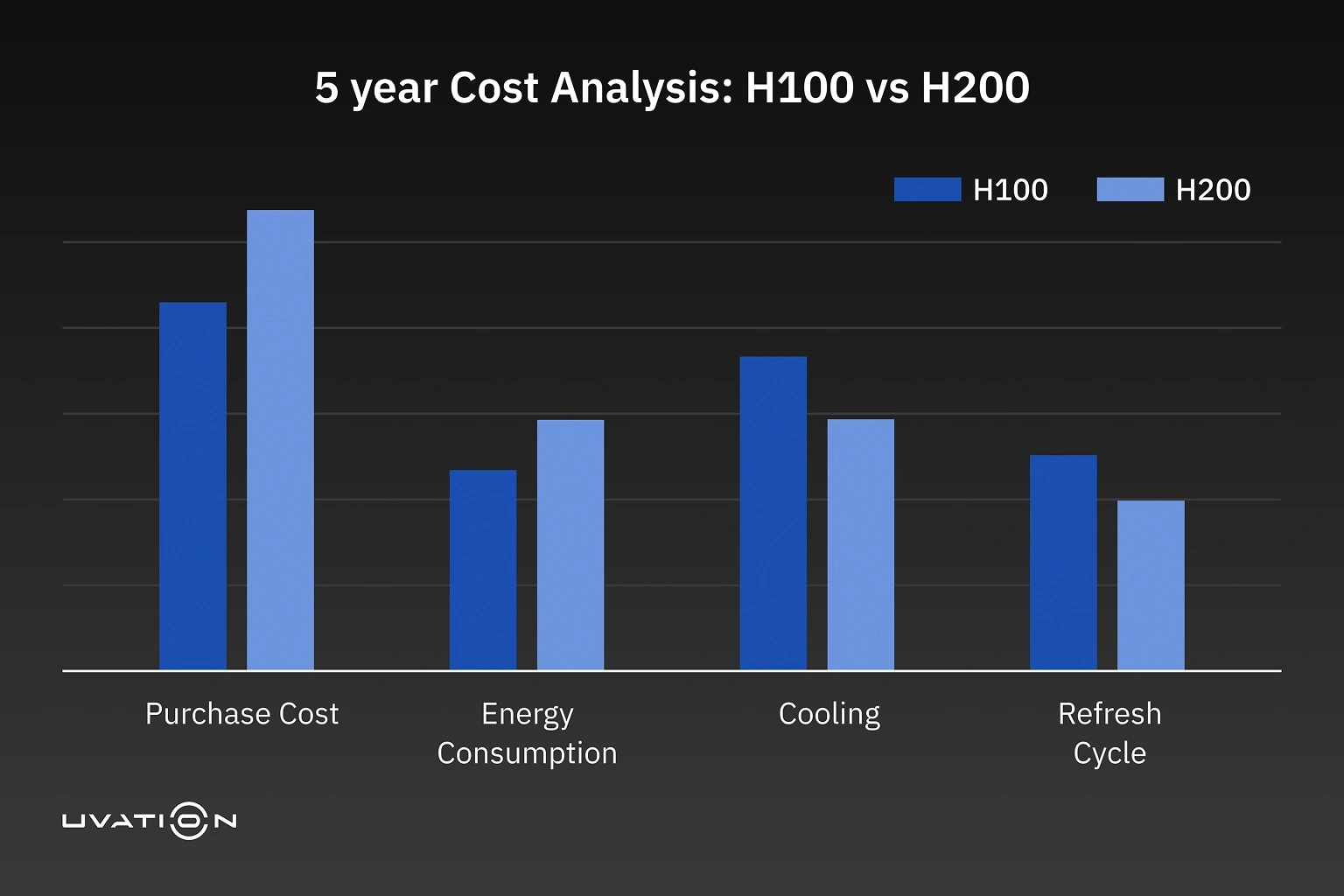
The H100 currently ranges from $30K to $40K per unit, depending on vendor and configuration. The H200? It’s expected to land 15–25% higher—likely between $34K and $50K.
That’s a steep delta. For clusters with 100+ GPUs, the difference adds up fast—$1M to $5M more in capex.
TCO: Where the H200 Pulls Ahead
Despite the shared 700W TDP, the H200 delivers 15–20% better performance per watt. Run it 24/7, and you’re saving $500–$1000 in energy costs per GPU annually.
Cooling sees similar gains. H200s generate slightly less heat, which can shave 5–10% off rack-level cooling expenses—worth $10K–$20K per rack over five years in large facilities.
Future-Proofing Value
The H200’s 141GB of HBM3e memory gives it headroom for tomorrow’s models. A 100GB VRAM workload today might need 150GB in 18 months. H100 users would need to upgrade. H200 buyers won’t.
ROI Math
In training, the H200 is ~20% faster. Inference? Twice as fast. That means faster time-to-market and double the throughput with the same hardware.
Better yet, the extra memory allows larger models to fit on fewer GPUs. A 175B parameter model that needs 8 H100s might run on 5 H200s. That’s a 37% cut in hardware—and fewer interconnect issues.
Delaying the Refresh Cycle
Buying H200s today could defer your next major upgrade by 2–3 years. For a 500-GPU fleet, that’s $15M–$25M in avoided spend when H300-class GPUs arrive.
6. The Verdict: When Does the H200’s Premium Pay Off?
For Immediate Needs
If your priority is speed-to-deployment and cost control, the H100 is still the GPU to beat. It’s proven, available (with some planning), and delivers strong ROI for most current workloads.
For Scaled, Future-Ready AI
The H200 justifies its premium for enterprises planning to scale aggressively—especially those leaning into cloud AI, vision models, or LLMs.
- Cloud Workloads benefit from shorter training and inference cycles, cutting pay-as-you-go costs.
- On-Prem Deployments get energy and cooling savings that compound over time.
- AI Innovators gain the memory and compute headroom to handle next-gen models without a refresh.
Bottom Line
The H200 isn’t just a spec bump. It’s a hedge against obsolescence and an investment in AI velocity. For CIOs with long-term ambitions, it can pay for itself in fewer nodes, faster throughput, and deferred upgrades.
But for others, the H100 delivers what matters now—reliably, and at a lower cost.
Conclusion
Choosing between NVIDIA’s H200 and H100 isn’t just about tech specs—it’s about aligning GPU strategy with enterprise timelines and risk tolerance.
Yes, the H200 brings 141GB of HBM3e, 2x inference gains, and future-proof architecture—but it comes with longer lead times and a 15–25% premium. The H100, while less scalable, remains a smart pick for teams with active workloads and tight procurement windows.
What CIOs Should Do Now:
- Audit Your AI Pipeline
Reserve the H200 for LLMs, multi-modal, and memory-bound use cases. Deploy H100s for general AI and mixed HPC workloads. - Compare Long-Term TCO, Not Just Sticker Price
Factor in energy, cooling, model fit, and upgrade cycles. - Secure Supply Chains Early
Partner with vendors like Semifly to run real-world pilots and lock in allocations before shortages hit.
Because in this market, your GPU isn’t just infrastructure. It’s your AI advantage.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now