FEATURED STORY OF THE WEEK
Redundant by Design: How NVIDIA H200 Power Management Empowers Real Enterprise AI

AI failures don’t always come from bad models — sometimes they come from a power glitch in a Tier-2 data center at 3 AM.
For enterprises deploying large language models (LLMs), the conversation can’t stop at GPU performance. It has to extend deeper — to power management, redundancy, and operational continuity.
Because when you’re training multi-billion-parameter models or serving millions of inference requests daily, any downtime isn’t just an inconvenience — it’s risk.
That’s where the often-overlooked story of NVIDIA H200 power management and redundancy architecture becomes critical.
Why does power and redundancy matter so much for LLM infrastructure?
Modern LLM workloads — especially retrieval-augmented generation (RAG), multimodal inferencing, or fine-tuning — demand sustained performance over long windows.
But they also come with real risks:
- Single-point power failure on a board can bring down training runs
- Unbalanced thermal profiles can throttle memory throughput
- Poor power provisioning can limit GPU performance even if specs are met
Most teams realize too late that GPU specs alone don’t deliver availability. It’s how they’re powered, cooled, and monitored that makes the difference.
How does NVIDIA H200 handle power management for enterprise AI?
The H200 is more than just an upgrade over the H100 — it’s built with infrastructure-grade safeguards:
| Feature | Function | Why It Matters |
|---|---|---|
| 700W Max Power Draw (per GPU) | Requires intelligent provisioning at rack level | Poor allocation leads to brownouts or performance capping |
| Dynamic Thermal Monitoring | Balances GPU core and HBM temperature zones | Prevents memory throttling under LLM burst workloads |
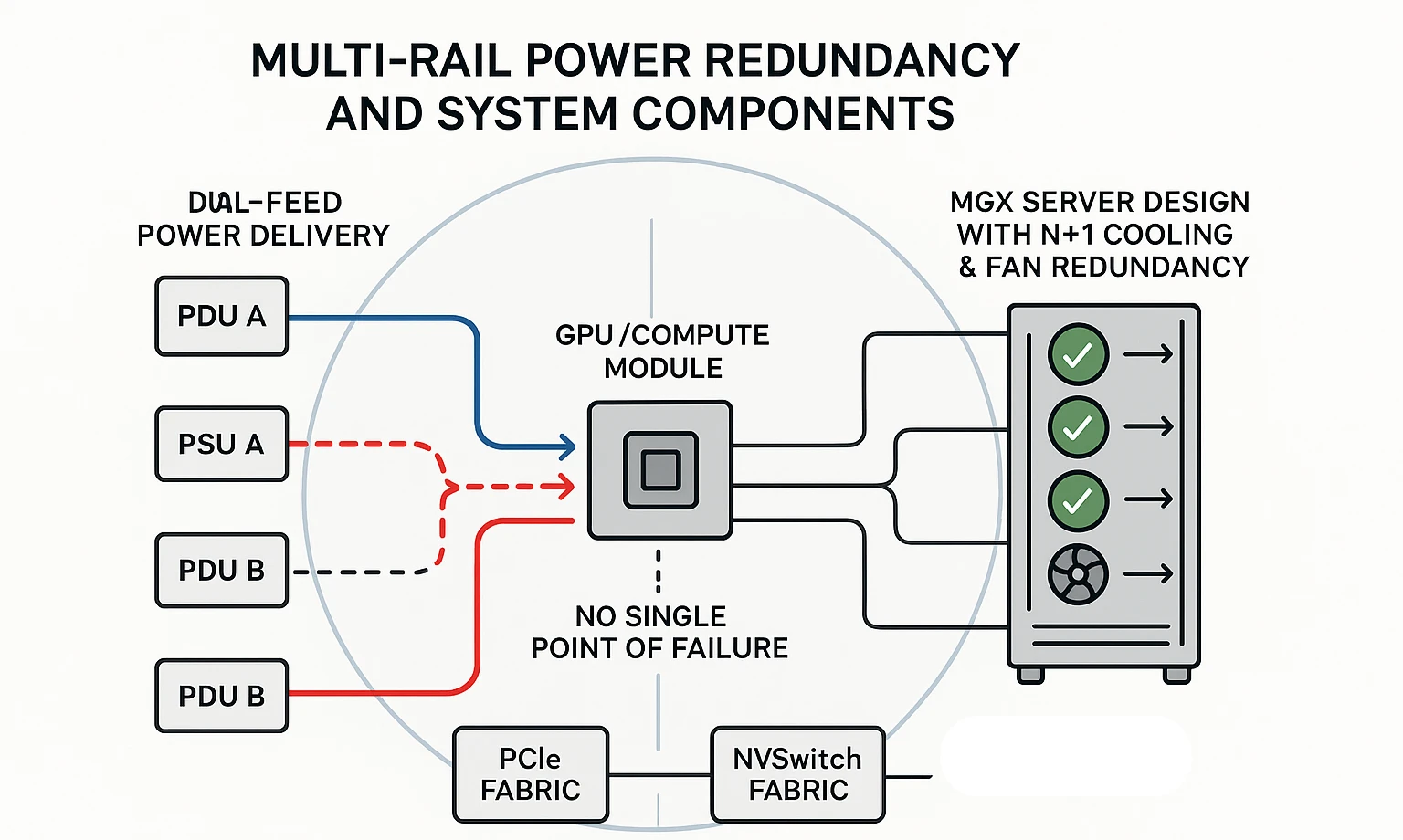
| Multi-Rail Power Redundancy Support | Supports dual PSU paths per server (via MGX, HGX, or BasePOD) | Avoids job kill if one power rail fails |
| Board-Level Telemetry Integration | Real-time power stats feed into orchestration layer | Enables workload-aware power throttling vs. blind failover |
These aren’t just electrical conveniences — they are operational requirements for teams running mission-critical AI workloads.

What makes NVIDIA H200 redundancy work beyond the GPU level?
Many H200 buyers don’t realize: true redundancy isn’t a feature of the chip — it’s a feature of the system around the chip.
At Semifly, we help enterprises deploy infrastructure where H200’s fail-safe features are fully enabled:
- Dual-feed power delivery using redundant PSUs and PDU channels
- MGX server design with N+1 cooling & fan redundancy
- NVSwitch and PCIe fabric separation to avoid interconnect failure cascade
- Job-aware failover that redirects workloads at the container layer, not just the hardware layer
And crucially — predictive alerts tied to H200’s onboard telemetry give operators time to respond before the model fails.
How does redundancy improve both uptime and model performance?
Let’s be real: most teams don’t talk about power management until something goes wrong.
But high-availability infrastructure isn’t just about uptime — it’s a performance enabler:
- You can push GPU utilization to >90% safely
- You can schedule longer fine-tuning cycles without kill risk
- You can serve multi-model traffic (e.g., LLM + Vision + RAG) on the same rack
- You can run night-time jobs confidently with remote operators
In short: better power management = higher model velocity + lower recovery cost.
And with H200’s capabilities, you’re already halfway there — if the system is designed correctly.
How does Semifly deliver power-optimized, fault-tolerant H200 deployments?
At Semifly, we don’t stop at “is the GPU powerful?”
We ask: “What happens if a fan dies in the middle of a sovereign AI workload?”
That’s why every H200 deployment includes:
- Redundancy mapping for rack-level and node-level faults
- H200 power telemetry integration into your monitoring stack (e.g. via IPMI, Prometheus, DGX BasePOD stack)
- Pre-tuned GPU performance thresholds based on power profiles
- Design validation for your use case — not just your hardware order

What’s the smartest way to deploy the NVIDIA H200 for LLMs?
You can’t unlock LLM performance with power capping.
You can’t prevent downtime with one PDU.
And you can’t scale AI unless the foundation is ready.
The NVIDIA H200 has the right power and redundancy tools built in — but only a well-architected stack unlocks them.
Let Semifly help you do that — from board to workload.
Book a power-readiness consultation today →



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now