FEATURED STORY OF THE WEEK
DGX B200 vs DGX H100 Benchmarks: A Deep Dive into NVIDIA’s Next-Gen AI Performance

As artificial intelligence models expand to trillions of parameters and combine visual, language, and reasoning capabilities, the performance demands on GPU systems have reached a new level. Organizations building these models need hardware that can sustain massive data movement, high memory bandwidth, and continuous workload scaling. The question for technical leaders is not whether existing GPU systems can keep up—but which platform delivers the most efficient path forward.
NVIDIA’s DGX H100 system, powered by the Hopper architecture, has been the performance benchmark for AI training and inference since its introduction in 2022. It enabled large enterprises and research centers to accelerate generative AI workloads and high-performance computing with unmatched reliability.
The newly released DGX B200 system, built on NVIDIA’s Blackwell architecture, marks a significant advance in AI infrastructure design. With enhanced GPU-to-GPU interconnects, increased memory capacity, and higher computational throughput, it is purpose-built for handling trillion-parameter models and real-time inference workloads.
This comparison between DGX B200 vs DGX H100 benchmarks explores measurable differences in compute power, networking architecture, energy efficiency, and system scalability—helping IT leaders understand where each system fits in today’s AI landscape.
1. Architectural Leap: Blackwell vs Hopper
The shift from NVIDIA’s Hopper to Blackwell architecture represents a major advancement in GPU engineering and system design. Both platforms serve high-performance AI workloads, but the DGX B200 redefines efficiency and throughput. For enterprises comparing DGX B200 vs DGX H100 benchmarks, understanding these architectural differences is essential to assess real-world performance gains.

GPU Architecture
The DGX H100 is powered by eight Hopper H100 Tensor Core GPUs. Hopper introduced features such as the Transformer Engine and FP8 precision to accelerate large language model training and inference. In contrast, the DGX B200 uses eight Blackwell B200 Tensor Core GPUs—each designed to support trillion-parameter AI models and large-scale inference tasks. Blackwell GPUs extend the concept of mixed-precision computing and deliver significantly higher throughput for FP8 and FP16 operations, which are central to today’s generative AI workloads.
Process Node and Design
Hopper GPUs are built on TSMC’s 4N process and feature 80GB of HBM3 memory per GPU. This design delivered a significant leap in energy efficiency and performance when introduced. Blackwell takes this foundation further with the refined TSMC 4NP process and an expanded 192GB of HBM3e memory per GPU.
HBM3e memory provides higher bandwidth and capacity, which helps sustain training and inference for extremely large AI models. Blackwell also introduces NVLink 5.0 connectivity, doubling the GPU-to-GPU bandwidth compared to Hopper’s NVLink 4.0, which directly impacts multi-GPU workload performance.
Core Improvement
At the core of the Blackwell GPU is a dual-die design, allowing the architecture to achieve approximately twice the throughput of Hopper for FP8 and FP16 workloads. This dual configuration improves efficiency in both compute and data transfer operations by allowing closer coordination between GPU cores.
For workloads that involve training very large neural networks or executing inference across massive datasets, this design reduces latency and enhances sustained performance. The result is smoother scaling for complex AI pipelines across DGX B200 systems, a key differentiator highlighted in NVIDIA’s performance data.
2. Benchmark Analysis: DGX B200 vs DGX H100
Performance comparisons between DGX B200 and DGX H100 reveal a major step forward in compute throughput, interconnect speed, and energy efficiency. NVIDIA’s internal testing and data from early HPC benchmarks confirm that Blackwell-based systems deliver higher sustained performance across both training and inference workloads. These gains are not limited to raw power; they extend to faster convergence times, better memory utilization, and lower total energy consumption per task.

Training Throughput
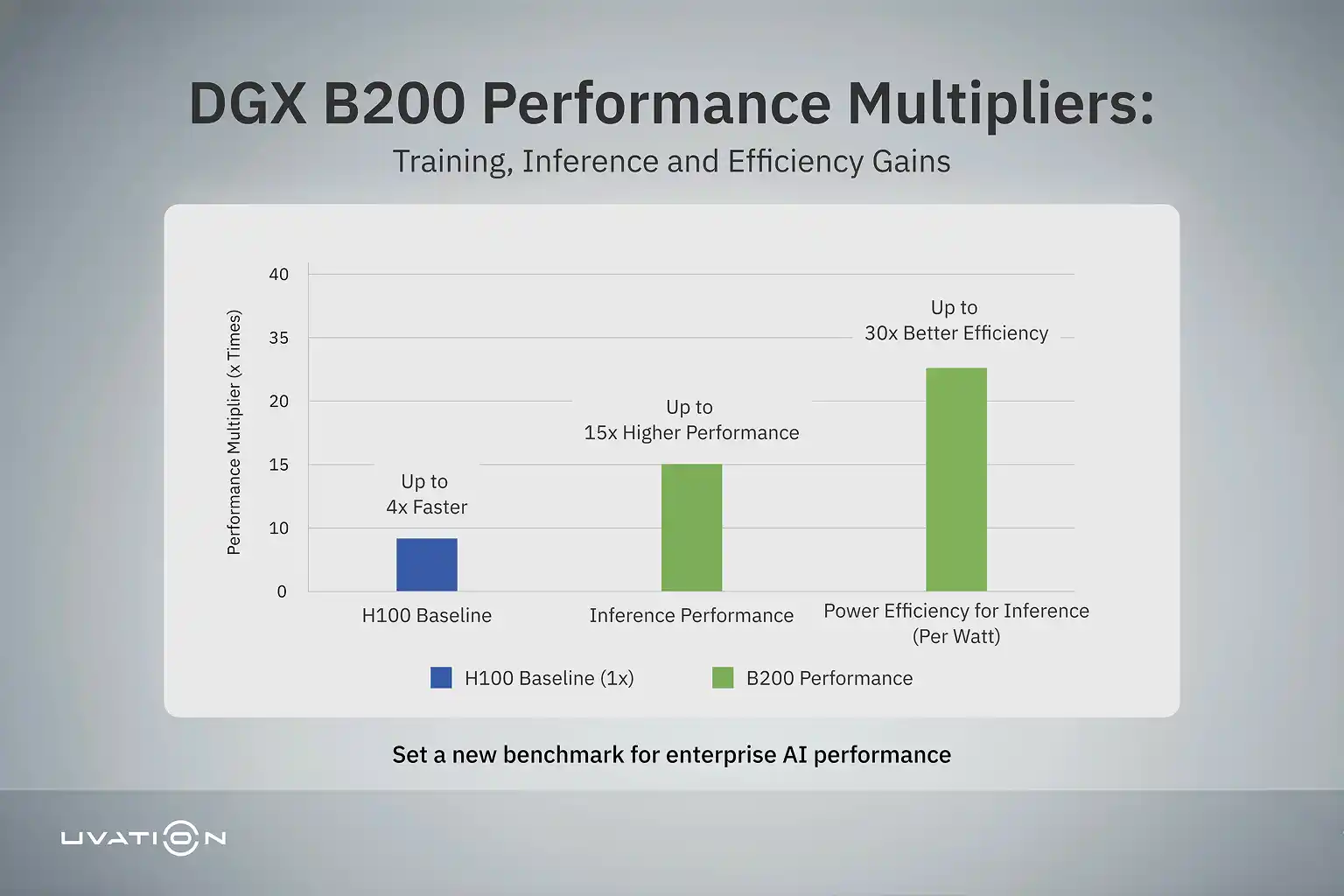
The DGX B200 demonstrates up to three times faster training performance than the DGX H100 when running large language models such as GPT and Mixtral. This gain comes from three factors: improved FP8 and FP16 compute performance, expanded HBM3e memory, and faster interconnect bandwidth.
The dual-die Blackwell GPU architecture allows data to flow between compute units more efficiently, reducing idle cycles during training. In large-scale AI systems, this translates into shorter training durations and more predictable scaling across multi-node clusters. For enterprises managing model training pipelines, these improvements reduce both time-to-insight and overall compute costs.
Inference Performance
Inference—the stage where trained AI models generate predictions or responses—places distinct demands on GPU hardware. The DGX B200’s architecture introduces up to 15 times higher performance for inference workloads compared to the DGX H100. This improvement comes from architectural refinements that maintain peak performance.
The use of FP8 precision further minimizes data movement and memory overhead, allowing inference pipelines to execute with higher throughput and lower energy draw. These gains have practical benefits in modern data centers.
NVLink Bandwidth
High-speed communication between GPUs is critical for both AI training and inference. The DGX H100 employs NVLink 4.0, providing 900GB/s of GPU-to-GPU bandwidth. The DGX B200 doubles this capability with NVLink 5.0, reaching 1.8TB/s per GPU. This advancement allows for faster data sharing between GPUs, minimizing bottlenecks in distributed AI workloads.
The higher bandwidth also improves efficiency when scaling to larger clusters, ensuring that multi-node systems maintain consistent performance across interlinked GPUs. For enterprises training trillion-parameter models, NVLink 5.0 provides the throughput required to maintain synchronization across hundreds of GPUs in parallel.
Table 1: DGX B200 vs DGX H100 – Benchmark Summary
| Specification | DGX H100 | DGX B200 |
|---|---|---|
| GPU | 8x H100 Tensor Core | 8x B200 Tensor Core |
| Architecture | Hopper | Blackwell |
| Memory per GPU | 80GB HBM3 | 192GB HBM3e |
| Interconnect | NVLink 4.0 (900GB/s) | NVLink 5.0 (1.8TB/s) |
| AI Training Throughput (LLMs) | Baseline 1x | Up to 4x |
| Power Efficiency | 1x | Up to 30x for inference |
3. Scalability and Networking Performance
Scalability defines how effectively a system performs when workloads increase across multiple GPUs or nodes. Both the DGX H100 and DGX B200 are engineered to operate as building blocks within NVIDIA’s DGX SuperPOD architecture—a large-scale AI infrastructure designed to handle demanding workloads such as large language model (LLM) training, simulation, and data-intensive analytics. The improvements in GPU interconnect and memory coherence in the DGX B200 directly impact how well these systems scale when deployed in large clusters.
DGX SuperPOD Integration
Both DGX systems use a combination of NVLink, NVSwitch, and InfiniBand to maintain high-speed connectivity within and across nodes. This configuration allows GPU clusters to function as a single, high-performance computing resource. The DGX H100 relies on NVLink 4.0 and NVSwitch 3 for intra-node communication, delivering 900GB/s of GPU-to-GPU bandwidth.
The DGX B200 advances this with NVLink 5.0 and NVSwitch 5, which doubles the communication bandwidth to 1.8TB/s per GPU. This improvement reduces latency across interconnected GPUs, leading to smoother synchronization during large-scale AI training.
NVLink 5 and Cross-Node Connectivity
The DGX B200 introduces NVLink 5 technology with 900GB/s GPU-to-GPU cross-node connections, extending high-speed communication beyond a single system. This capability allows multiple DGX B200 nodes to communicate as part of a larger AI cluster with minimal data transfer bottlenecks. When combined with InfiniBand networking, it ensures balanced throughput across nodes, critical for LLMs that span hundreds of billions or trillions of parameters. The consistent bandwidth between nodes ensures uniform training performance and eliminates the slowdowns often seen in large distributed systems.
Unified Memory Coherence and GPU Scaling
A major advancement in the DGX B200 system is its enhanced NVLink memory coherence. This feature enables up to 576 GPUs to share data in a unified memory space, improving efficiency when models are distributed across multiple nodes. In practical terms, this allows AI training frameworks to treat large GPU clusters as a single memory pool, reducing the need for frequent data replication between devices.
This improvement supports faster convergence for complex AI models and improves resource utilization across the cluster. The DGX H100, while powerful, is limited to smaller unified configurations by comparison, giving the DGX B200 a clear advantage in cluster-scale training performance.
Table 2: Networking and Scaling Comparison
| Feature | DGX H100 | DGX B200 |
|---|---|---|
| NVLink Fabric | NVLink 4 + NVSwitch 3 | NVLink 5 + NVSwitch 5 |
| Bandwidth | 900GB/s | 1.8TB/s |
| Interconnect Topology | Hybrid Cube Mesh | NVLink Mesh Fabric |
| Maximum Cluster GPUs | 256 | 576 |
4. Energy Efficiency and Sustainability
While raw performance is essential, modern AI infrastructure must also manage power and thermal constraints. The DGX B200 introduces architectural refinements that improve energy efficiency per operation. In this section, we compare how Blackwell’s features reduce energy cost and examine implications for the total cost of ownership.
DGX B200 Efficiency Leap
The Blackwell architecture enables fine-grained power gating, which means idle portions of the GPU can be shut off or slowed dynamically. This reduces waste when full capacity is not needed. In addition, Blackwell’s support for FP8 precision further lowers energy consumption for inference and mixed precision workloads, because fewer bits are moved or computed per operation. Early reports suggest that Blackwell achieves about 1.7× better efficiency than Hopper when normalized to FP16 workloads.
The DGX B200 system is rated at a maximum power draw of ~14.3 kW under full load. This figure provides headroom for other system components while maintaining energy margins for cooling and operational overhead.
Because Blackwell is more efficient per operation, an AI cluster using DGX B200 systems can handle more throughput for the same wattage—or maintain throughput with lower power draw.
DGX H100 Baseline
Hopper introduced its own energy-saving features. Notably, the Transformer Engine in H100 can dynamically cast operations between FP8 and FP16 precision. This flexibility reduces power and memory usage for transformer-based models.
NVIDIA also claims that H100 accelerates inference by up to 30x over earlier architectures, in part due to these precision optimizations. In effect, H100 established a strong energy-efficiency benchmark for GPU-based AI systems.
Operational Impact and TCO
For enterprises, the critical metric is intelligence per joule—that is, how much useful AI work is done for each unit of energy consumed.
Because DGX B200 systems deliver higher throughput and better per-watt efficiency than DGX H100, they reduce the electricity and cooling costs per model training or inference cycle. Over time, savings in operational expenditure can offset capital costs.
In facilities constrained by power or cooling capacity, the better efficiency of B200 allows for denser deployments or supports larger-scale systems without exceeding infrastructure limits.
In short, when comparing DGX B200 vs DGX H100 benchmarks, energy metrics are as important as raw throughput. The B200’s advantage in joules-per-inference or joules-per-training-run is a key factor for decision-makers evaluating long-term ROI.
5. The Road Ahead: DGX B200, DGX H200, and Beyond
This section looks ahead to what lies between and beyond the current platforms. We examine how the DGX H200 fits into NVIDIA’s product progression, how the DGX B200 positions itself in that trajectory, and what the larger software and hardware ecosystem readiness means for enterprises adopting these systems.
DGX H200 Context
The DGX H200 is built around the H200 Tensor Core GPU, which represents an incremental evolution of the Hopper line. It brings enhancements like HBM3e memory and increased interconnect bandwidth, while retaining much of the architectural heritage of Hopper.
In terms of performance, the DGX H200 delivers up to 32 petaFLOPS in FP8 workloads, with doubled networking bandwidth relative to earlier DGX A100 generations. The H200 bridges the gap between earlier Hopper-based systems and the newer Blackwell generation—offering improved memory bandwidth, enhanced GPU-to-GPU communication, and better throughput for many AI workloads, albeit without some of Blackwell’s architectural changes.
The H200 is thus a “mid-point” in the evolution—useful for organizations that may not yet require the full Blackwell leap but seek incremental improvements in memory and bandwidth. Its adoption helps smooth migrations across generational transitions.
Positioning of DGX B200
While the DGX H200 offers upgrades over H100, the DGX B200 marks a true generational shift in architecture, performance, and scaling. With Blackwell GPUs, NVLink 5.0, enhanced memory coherence, and higher per-GPU bandwidth, the B200 is better suited for the largest AI workloads: foundation model training, large-scale inference, multimodal AI, and simulation tasks.
In environments where models exceed terabytes in parameter space or where latency and throughput are critical, the B200’s architecture gives it a stronger foundation. As enterprises evaluate DGX B200 vs DGX H100 benchmarks, they should also consider whether DGX H200 could serve as a stop-gap solution or an intermediate upgrade, depending on workloads and investment timing.
In many cases, organizations launching new AI infrastructure may find it justifiable to move directly to B200. Its improvements in interconnect, GPU memory, and compute density make it better suited to meet longer-term demands. Over multiple upgrade cycles, the TCO benefits of B200 may outweigh stepping through an intermediate H200 tier.
Ecosystem Readiness & Software Alignment
Adoption of high-end GPU infrastructure is not just about hardware. Software support, APIs, orchestration tools, and deployment frameworks matter greatly. Fortunately, NVIDIA positions the DGX B200 within a mature software stack that includes NVIDIA AI Enterprise and support for Omniverse Cloud APIs.
- NVIDIA AI Enterprise offers a validated AI software suite that spans frameworks, containers, orchestration, monitoring, and deployment, making it easier for organizations to use advanced GPU systems in production environments.
- Omniverse Cloud APIs allow developers to connect simulation, digital twin, and real-world data workflows via programmability in 3D and physical AI applications.
- Systems like DGX are also often certified for enterprise simulation workloads through Omniverse Enterprise, making them relevant for robotics, design, engineering, and industrial AI.
Because the DGX B200 is already aligned with these software layers, enterprises can more easily adopt it without waiting for ecosystem maturity. In contrast, the H200, being closer to Hopper, may not fully exploit newer features in Omniverse or newer memory coherence APIs.
Overall, when judging DGX B200 vs DGX H100 benchmarks, organizations should not ignore how well each platform aligns with their software tools, deployment models, and future application paths.
Conclusion: The New Benchmark for Enterprise AI
The DGX B200 represents a decisive evolution in NVIDIA’s enterprise AI and HPC systems. Compared with the DGX H100, it doubles throughput, enhances GPU-to-GPU bandwidth, and delivers significant efficiency gains through architectural redesign and improved power management. For enterprises, these advances translate into faster model convergence, reduced training cycles, and improved power economics, all essential for scaling large language models and simulation workloads effectively.
Organizations upgrading from DGX H100 to DGX B200 can expect measurable results: faster model training, better interconnect performance, and substantial reductions in total cost of ownership. For those planning infrastructure modernization, Semifly’s infrastructure specialists help evaluate workload readiness, architect efficient DGX B200 clusters, and align deployments for maximum return on investment and sustained performance.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now