FEATURED STORY OF THE WEEK
NVIDIA SuperNIC: The Hidden Powerhouse of AI Cloud Data Centers
When you think about AI cloud data centers, your focus naturally goes to GPUs—they’re the powerhouses of AI compute. But what if the real game-changer lies in how GPUs are connected, not just how many you deploy?
That’s where NVIDIA SuperNIC steps in. It’s not a marketing gimmick—SuperNIC is the foundation for high-throughput, low-latency infrastructure required by ultra-scale AI workloads.

Addressing the Networking Bottleneck in AI Cloud Data Centers
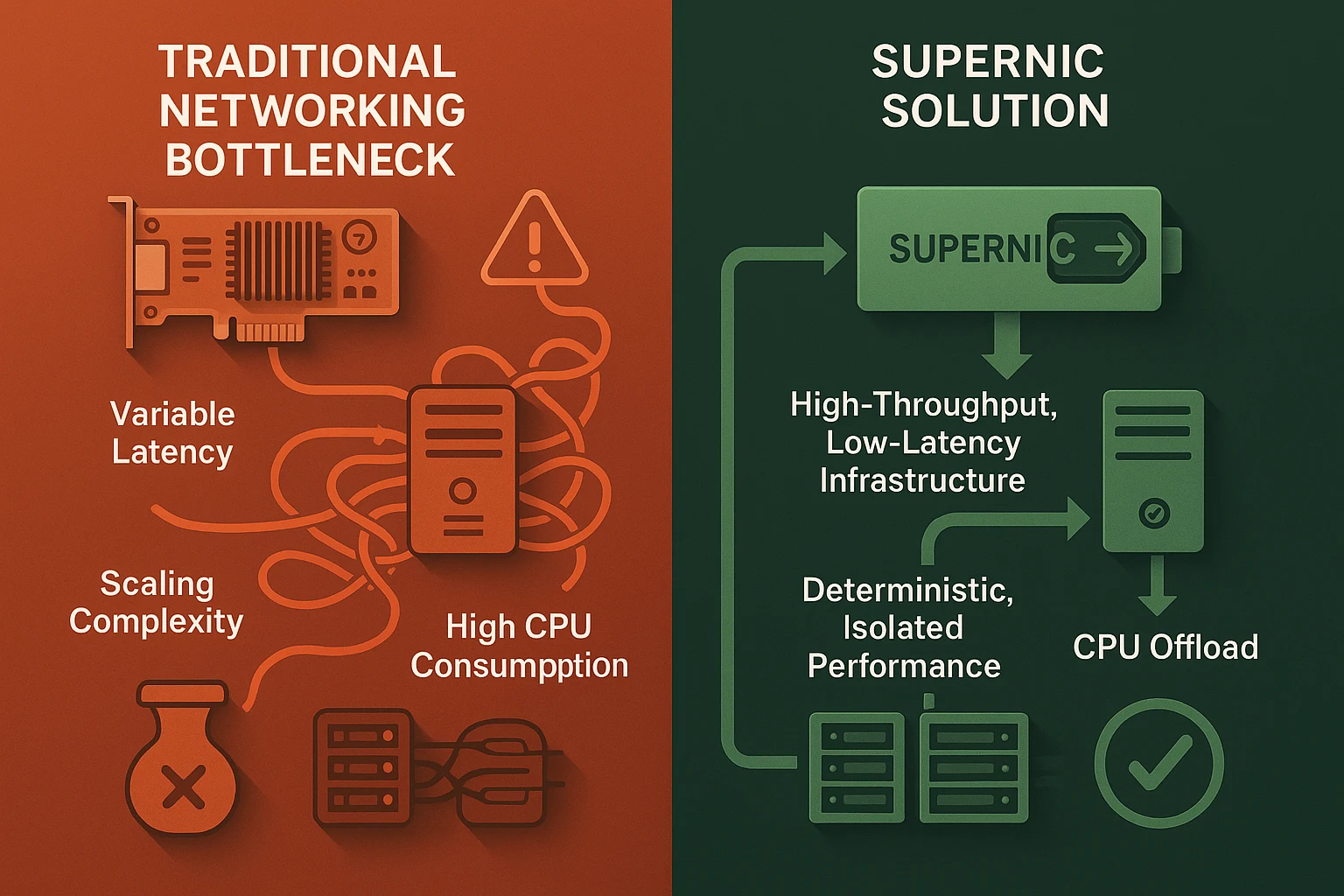
AI workloads—especially distributed model training and inference—place brutal demands on networking. Traditional Ethernet just wasn’t built for this:
- It can’t guarantee microsecond-level latency.
- Scaling bandwidth to match GPU demands is costly and complex.
- It consumes CPU cycles during data movement, reducing AI efficiency.
- Network jitter undermines synchronization in multi-node clusters.
This isn’t just a networking challenge—it’s an AI infrastructure bottleneck. The NVIDIA SuperNIC is purpose-built to remove that bottleneck.
What Makes NVIDIA SuperNIC Essential for AI Cloud Data Centers
Per NVIDIA’s networking architecture, SuperNICs are a new breed of Ethernet accelerators engineered for massive-scale AI environments:
- BlueField-3 SuperNIC — 400 Gb/s RDMA over Converged Ethernet (RoCE), delivering deterministic, isolated performance and secure multi-tenancy.
- ConnectX-8 SuperNIC — Supports up to 800 Gb/s RDMA, accelerating generative AI workloads and enabling hyperscale fabric deployments.
These aren’t incremental upgrades—they represent a shift in architecture, where GPUs and network are deeply integrated to power AI compute at scale.
A key NVIDIA platform—the Spectrum-X Networking Fabric, which combines Spectrum switches with SuperNICs—boosts generative AI network performance by 1.6× compared to traditional Ethernet.
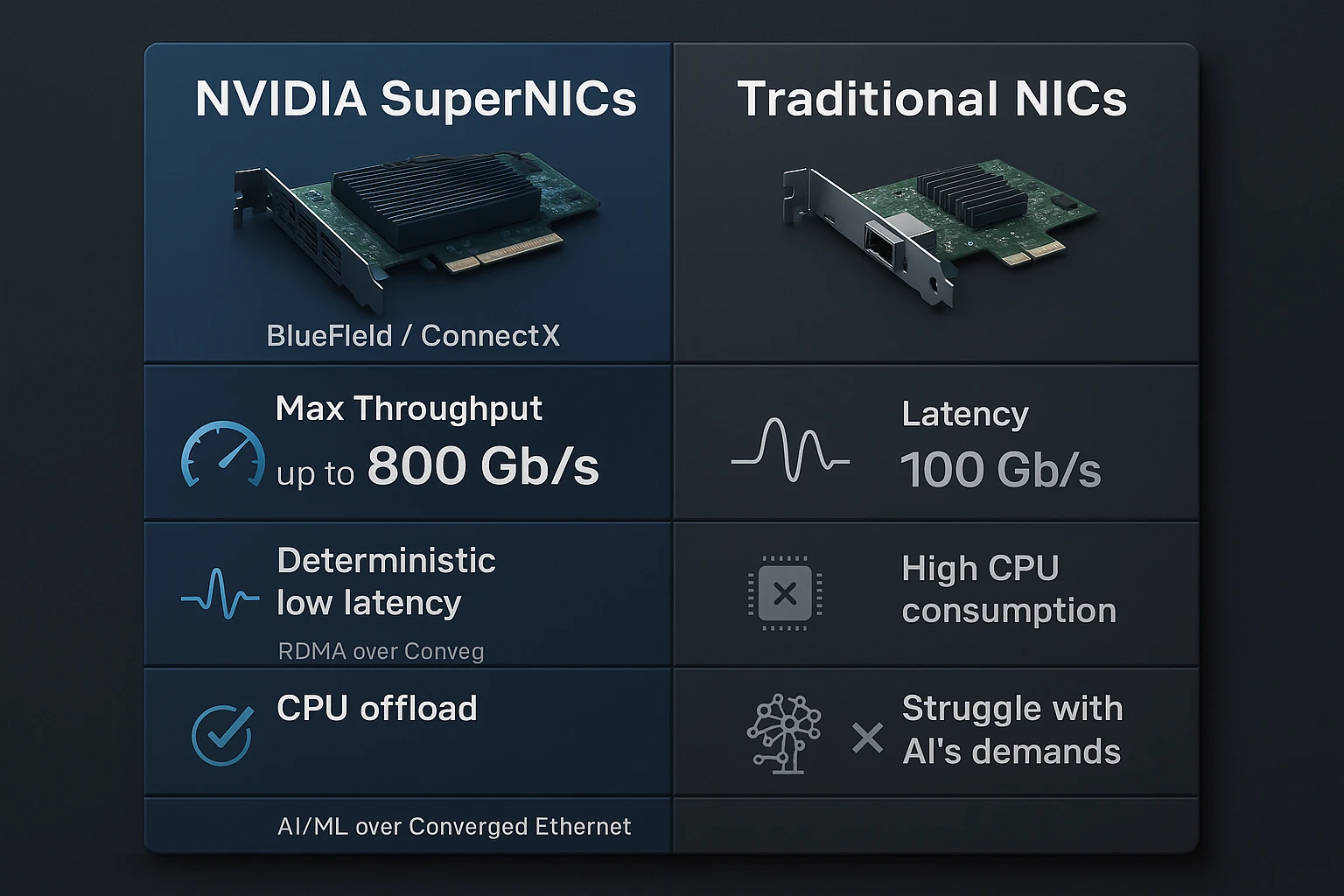
SuperNIC vs Traditional NICs: Why the Difference Matter
| Feature | Traditional NICs | NVIDIA SuperNIC (BlueField/ConnectX) |
|---|---|---|
| Max Throughput | Up to 100 Gb/s | Up to 800 Gb/s |
| Protocol | Standard TCP/IP | RDMA (RoCE) with GPUDirect support |
| CPU Involvement | High (for packet processing) | Offloaded (freeing CPU cycles for AI workloads) |
| Latency | Variable (unpredictable) | Deterministic low-latency |
| Multi-Tenant Isolation | Limited | Secure, hardware-enforced |
| AI/ML Optimization | Not AI-specific | Designed for LLM training and inference |
| Fabric Integration | Manual setup | Integrated with Spectrum-X Ethernet Fabric |
This leap isn’t just technical—it’s architectural. SuperNICs create predictability, scale, and security where traditional NICs introduce friction.
SuperNIC in Supercharged AI Fabrics
In an AI cloud data center—such as Semifly-powered deployments—the infrastructure fabric is not just connected, it’s cohesive:
- GPU-server clusters linked via SuperNICs and Spectrum switches form unified compute domains.
- RDMA (RoCE) bypasses CPU and system memory, accelerating inter-GPU communication.
- Multi-tenant isolation ensures noiseless AI scaling across teams in shared environments.
- Secure, deterministic performance keeps latency-sensitive inference accurate and efficient.
In short, SuperNIC becomes the nervous system of your AI platform.
Semifly’s Advantage: Deploying SuperNIC-Optimized AI Infrastructure
At Semifly, we specialize in end-to-end AI infrastructure deployment—selecting the right compute, networking fabric, and orchestration layer for your needs.
By designing AI cloud environments with SuperNIC-enabled fabrics, Semifly helps organizations unlock:
- Scalable GPUDirect RDMA networks for multi-rack training clusters.
- Secure AI multi-tenancy, perfect for shared compute environments like universities or federated enterprises.
- Consistent performance under varying AI workloads, from LLM fine-tuning to real-time inference.
We connect NVIDIA-class hardware (SuperNICs, GPUs, Spectrum switches) with our deployment blueprints and automation stack—so AI cloud data centers hit performance goals from Day 1.
Final Takeaway: SuperNICs Are the AI Edge You Didn’t Notice
While GPUs get all the attention, it’s NVIDIA SuperNIC that delivers the connectivity foundation enabling real-time, scalable AI compute. In AI cloud data centers, network performance isn’t auxiliary—it’s central.
If you’re architecting multi-node training clusters or private AI clouds, let’s incorporate SuperNICs into a deployment that’s efficient, secure, and predictive.
→ Talk to Semifly’s AI Infrastructure Team — we’ll help you map the right data fabric for your AI workloads.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now