Data Sovereignty vs Data Residency vs Data Localization in the AI Era
In today’s digital world, data constantly flows across borders, from social media posts to cloud-stored business records. This global movement creates complex challenges: data sovereignty (who legally controls data based on its location), data residency (where data is physically stored), and data localization (laws requiring data to stay within a country). These concepts are rising in importance due to rapid AI advancements, which demand massive datasets often scattered worldwide, and strict regulations like the GDPR.
Businesses face a critical question: How do these rules intersect, and why do they matter? Ignoring them risks heavy fines, blocked data transfers, or losing customer trust. Simply put, where data lives and who governs it directly impacts AI innovation and global operations.
1. What Is Data Sovereignty, Data Residency, and Data Localization?
Navigating data rules starts with three key ideas. Though they sound similar, each plays a unique role in how data is stored and controlled globally. Let’s break them down clearly.
Data sovereignty means data is subject to the laws of the country where it is located. For example, if customer data is stored in Germany, German privacy laws control how that data is used or accessed. This legal control affects businesses using AI, as training data must comply with local rules. The EU’s GDPR is a well-known sovereignty law.
Data residency is about where data is physically stored. It could be in a server farm in Canada or an Australian cloud center. Residency involves no legal requirements—it’s purely a business choice or customer request. Companies might pick residency for faster data access or to meet client preferences.
Data localization goes further: it forces data to stay within a country’s borders. Governments impose these rules for security or privacy. For instance, China’s PIPL law requires personal data to be processed domestically. Russia’s Federal Law No. 242-FZ similarly mandates local storage of citizen data.
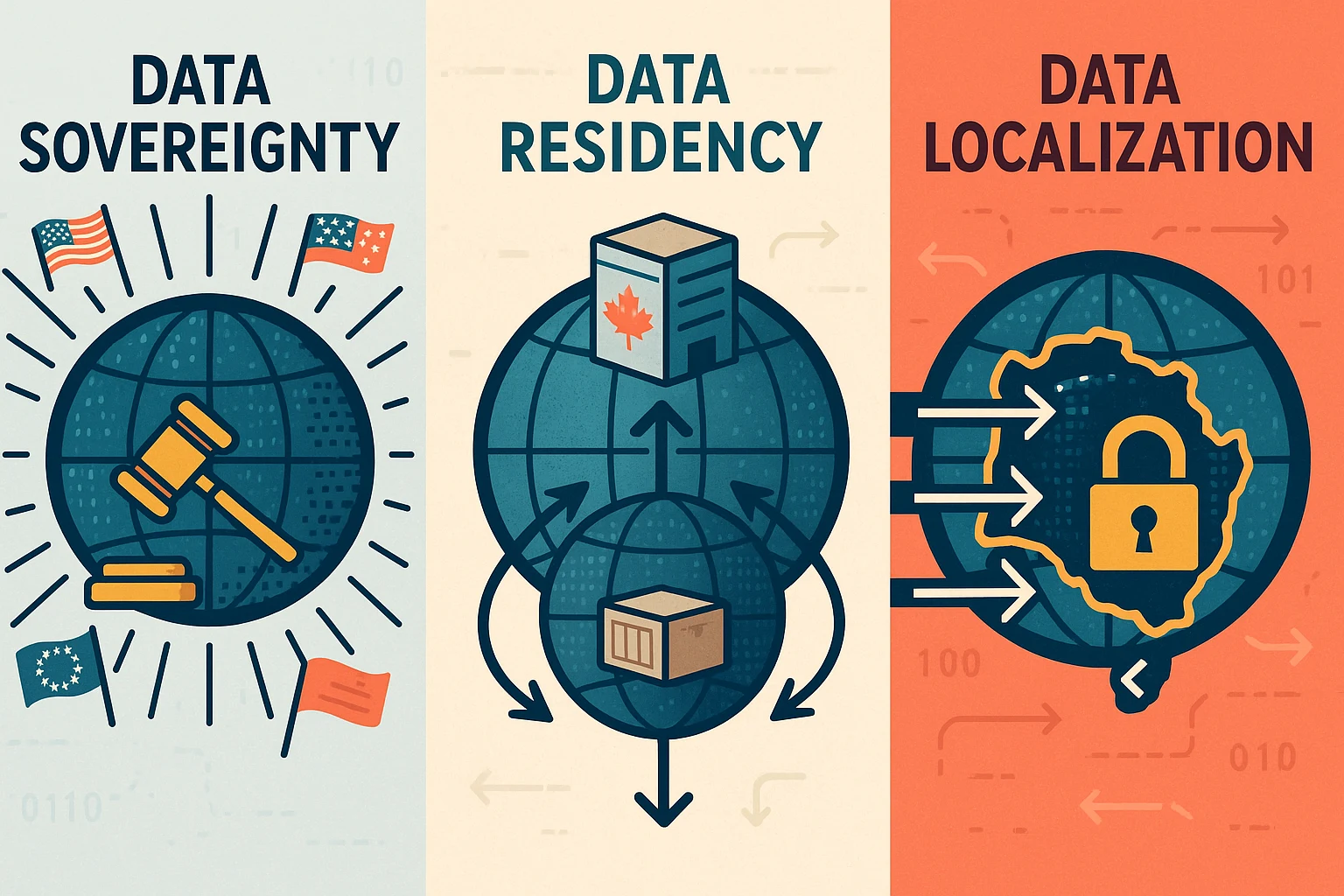
Key differences simplified:
- Sovereignty = Legal authority (e.g., GDPR).
- Residency = Physical location (e.g., choosing a Toronto data center).
- Localization = Legal requirement to keep data local (e.g., China’s PIPL).
Why This Matters for AI:
Data sovereignty and AI are deeply linked. AI systems using sovereign data must follow strict local laws, impacting how models are trained. For example, GDPR-compliant data can’t freely cross borders for AI training without safeguards.
2. How Do Data Sovereignty and Data Residency Interact?
Data sovereignty and data residency often work together but aren’t the same. Understanding their relationship helps businesses avoid legal risks and design efficient systems, especially with AI.
Residency supports sovereignty. When data is stored locally (residency), it naturally falls under that country’s laws (sovereignty). For example, keeping EU customer data in Frankfurt ensures GDPR compliance. This simplifies legal adherence for businesses using AI in regulated regions.
Sovereignty can exist without residency. Cloud giants like AWS or Microsoft Azure can store data physically outside a country (e.g., EU data in the US) while contractually committing to following that country’s laws. They achieve this through legal instruments like Standard Contractual Clauses (SCCs), essentially binding the foreign data center to the rules of the country where the data originated. However, this separation adds legal and operational complexity.
This complexity is amplified by how hyperscalers operate. To ensure resilience and performance, they automatically distribute and replicate data across their vast global networks. A file uploaded in Paris might be backed up to Singapore. This global distribution directly clashes with data sovereignty laws, which demand that data remains under the legal jurisdiction and physical control of one specific nation. Furthermore, this distribution can introduce latency, impacting AI workloads that require real-time, low-latency access to data.
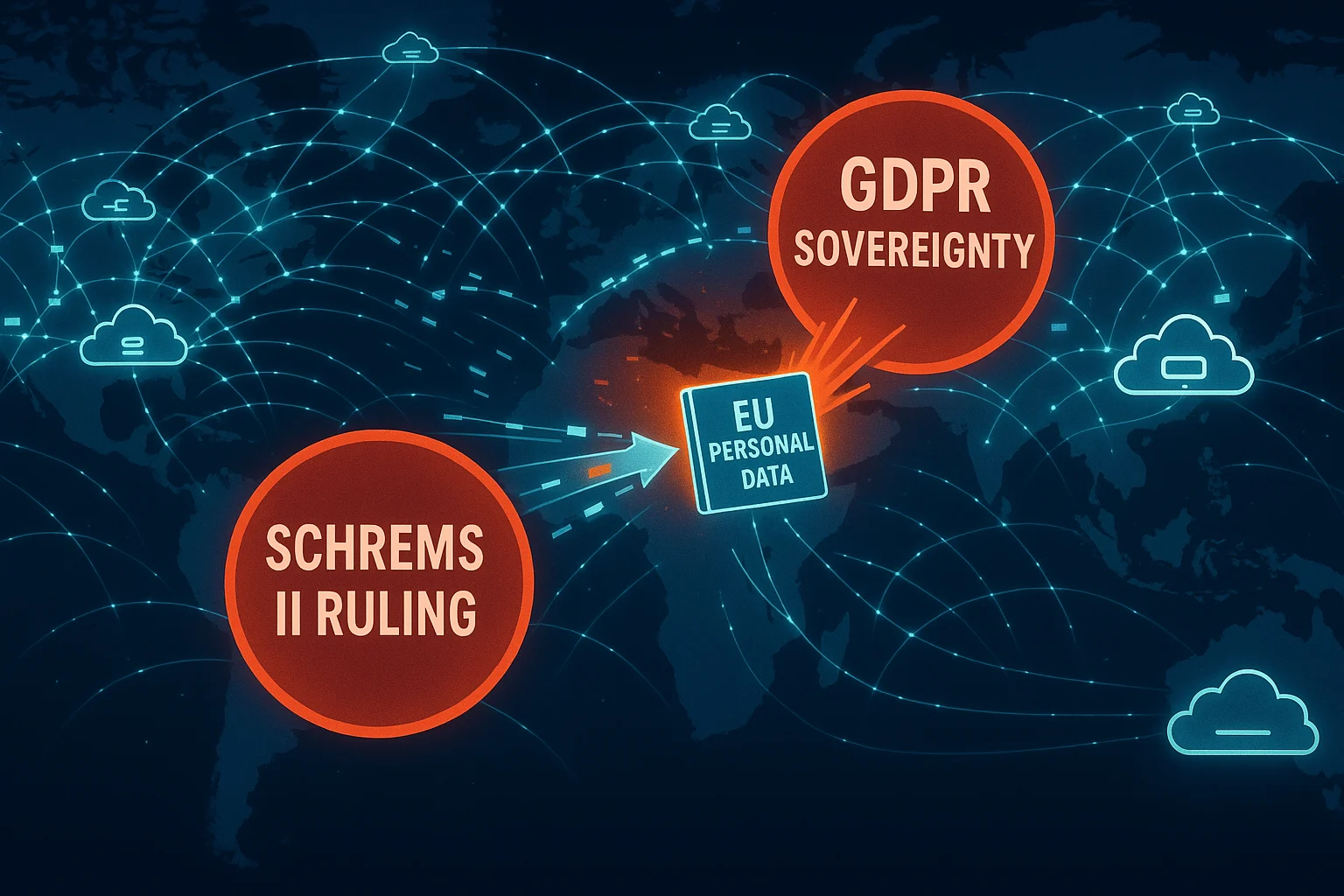
The real-world consequences are illustrated by rulings like Schrems II (2020). The Court of Justice of the European Union (CJEU) invalidated the EU-US Privacy Shield framework because US surveillance laws were deemed to grant authorities excessive access to EU personal data stored in the US. This violated the core principle of GDPR sovereignty – that EU data subjects are protected by EU law, regardless of where the data is processed.
Schrems II underscores a critical lesson: No legal agreements can fully overcome the risk posed by conflicting national laws in the data’s physical location. Sovereignty concerns can ultimately force a complete shift in residency strategies.
Table: Comparing Data Sovereignty and Residency
| Aspect |
Data Sovereignty |
Data Residency |
| Focus |
Legal jurisdiction |
Physical location |
| Primary Driver |
National laws (e.g., GDPR, CCPA) |
Business/contractual agreements |
| Cloud Impact |
Limits cross-border data transfers |
Influences data center selection |
| AI Implication |
Affects training data legality |
Determines compute infrastructure |
3. Why Is Data Localization Surging Globally?
Governments worldwide are tightening data rules, with many countries now enacting localization laws. This surge stems from three key drivers reshaping digital borders.
- National Security: National security concerns push countries like Russia to mandate local data storage. Laws such as Russia’s Federal Law No. 242-FZ require citizen data to stay within physical borders. This aims to prevent foreign surveillance or cyberattacks.
- Privacy Concerns: Privacy protections drive regulations like the GDPR. Though not purely localization-focused, GDPR’s strict rules on cross-border data flows encourage de facto localization. Companies often keep EU data local to avoid complex compliance.
- Economic Control: Economic control motivates laws such as India’s DPDP Act 2023. By forcing data to remain domestic, governments boost local tech industries. It also ensures tax revenue from digital services stays in-country.
Fragmented compliance creates hurdles. Brazil’s LGPD and South Korea’s PIPA differ from GDPR in enforcement and scope. Modern businesses must navigate conflicting rules, raising legal risks and operational delays.
Costs escalate under localization. Building local data centers or using region-locked clouds (e.g., Azure China) can double infrastructure expenses. Smaller firms struggle with these investments.
Localization also impacts AI initiatives significantly. Localization traps training data within borders, starving AI models of diverse global inputs. This limits scalability and innovation—a model trained only on French data may fail in Asia.
GDPR and AI intersect critically here. GDPR’s restrictions on international data transfers force AI developers to localize training data for EU users, fragmenting development efforts.
4. How Does Data Sovereignty Shape AI Development?
Data sovereignty isn’t just a compliance checkbox—it actively molds how AI systems are built and used. As laws tighten globally, AI developers face new constraints and ethical dilemmas.
Training data faces strict consent rules. Sovereign laws like GDPR’s Article 22 limit automated decision-making using personal data. For example, an AI credit-scoring model in Europe requires explicit user consent and human oversight. This restricts datasets available for training.
Bias risks escalate with localized data. When AI models train only on region-specific data (e.g., German healthcare records), they perform poorly elsewhere. This worsens fairness gaps—a hiring AI trained on homogeneous data may discriminate globally.
Deployment requires local rule compliance. AI inferences (outputs) must follow sovereignty laws where used. In France, health data processing demands stricter consent than in the U.S. An AI symptom checker must adapt according to the market or risk fines.
The EU’s AI Act intensifies sovereignty. High-risk AI systems (e.g., facial recognition) must use sovereign data and ensure traceability. Non-EU companies must appoint EU-based legal reps, extending jurisdiction beyond physical residency.

Mitigation strategies are evolving:
- Federated Learning: Trains AI across devices without moving raw data (e.g., phones analyzing local text to improve keyboards).
- Synthetic Data: Generates artificial datasets that mimic real patterns, avoiding privacy laws.
- Sovereign Clouds: Platforms like Gaia-X provide EU-controlled infrastructure for sensitive AI workloads.
Data sovereignty and AI are now inseparable. Ignoring sovereignty risks flawed models, legal penalties, or market exclusion—especially with a majority of countries drafting similar laws.
Table: AI Challenges Under Data Sovereignty
| AI Phase |
Sovereignty Impact |
Solution Example |
| Data Collection |
Consent/legal basis required (GDPR Art. 6) |
Anonymization; granular opt-ins |
| Model Training |
Cross-border data transfers restricted |
Federated learning; local hosting |
| Inference |
Outputs subject to local laws (e.g., explainability) |
On-premises deployment |
5. What Role Does GDPR Play in Governing AI?
The GDPR isn’t just about data privacy—it’s a powerful regulator of artificial intelligence. Its rules directly limit how AI systems handle personal data throughout their lifecycle – collection, processing, and prediction.
Purpose limitation (Article 5) mandates AI to use data only for explicitly defined objectives. For example, an AI trained to detect fraud cannot repurpose customer data for advertising. This stops “function creep” where AI expands beyond its original, consented purpose.
The right to explanation (Article 22) lets users demand clarity for automated decisions. If an AI rejects a loan application, the bank must explain how and why. This prevents “black box” AI that operates without transparency.
Data minimization (Article 5) clashes with AI’s inherent need for large amounts of data. AI developers can’t hoard excessive user details. They must collect only what’s essential—like a health AI using patient age and symptoms, not full medical histories.
GDPR extends EU sovereignty globally. Even non-EU companies must comply if they handle EU residents’ data. Fines reach €20 million or 4% of global revenue for severe violations. This makes GDPR and AI compliance unavoidable for international businesses.
The real-world impact of GDPR and AI regulation is illustrated by enforcement actions like Italy’s temporary ChatGPT ban (2023). Italy’s privacy authority (Garante) blocked the service citing specific GDPR breaches: inadequate age verification for minors and a failure to transparently disclose data processing practices. OpenAI was forced to implement disclosures, opt-out mechanisms, and an age gate to resume operations.
6. Can Businesses Navigate These Complexities?
Navigating data sovereignty, residency, and localization feels daunting. But proactive strategies can turn compliance into competitive advantage. Here’s how forward-thinking companies adapt.
- Master Data Visibility: The essential first step is comprehensive data mapping. Tools like IBM DataStage provide real-time tracking of where data resides, moves, and is processed. This visibility is crucial for data sovereignty and AI, enabling early detection of risks – such as GDPR-protected training data inadvertently flowing to non-compliant cloud regions.
- Leverage Adaptive Infrastructure: Hybrid cloud solutions, like AWS Outposts, deploy localized cloud resources directly within regulated jurisdictions. This satisfies strict residency requirements while maintaining efficient global access under sovereign control. This balance is vital for data sovereignty and AI, particularly when training models on sensitive datasets that cannot cross borders.
- Automate Proactive Compliance: Technology itself can be harnessed to manage sovereignty. AI-driven Data Protection Impact Assessments (DPIAs) continuously scan systems, identifying potential sovereignty gaps before they become violations. For instance, they can flag if health data used in a diagnostic AI model lacks the specific GDPR-compliant consent required, allowing remediation ahead of audits.
Emerging solutions further ease the burden:
Sovereignty-as-a-Service: Many cloud platforms offer pre-configured, compliant storage and compute environments. Businesses sidestep costly local infrastructure builds while ensuring data sovereignty and AI workloads inherently meet complex regional legal frameworks.
Global Standards Convergence: Initiatives like the OECD’s AI Principles work towards harmonizing sovereignty and AI governance rules internationally. Reducing fragmentation allows an AI model developed and trained under Canadian standards to be deployed in Japan with significantly less legal rework, streamlining global innovation.
Conclusion
Data sovereignty, residency, and localization are no longer niche concerns; they are critical pillars of responsible AI and global business. Where data lives, who controls it, and how it moves directly shape AI innovation.
GDPR sets a high bar, proving that strict sovereignty rules can coexist with technological progress. However, new laws like India’s DPDP Act or Brazil’s LGPD are fragmenting compliance. This creates a complex patchwork for multinational AI deployments.
The solution lies in proactive strategy:
- Invest in adaptable infrastructure like sovereign clouds to dynamically meet residency and localization demands.
- Build ethical AI frameworks that bake GDPR and AI principles—like data minimization and explainability—into design.
- Treat data sovereignty and AI as intertwined challenges, not separate checkboxes.
Businesses mastering this balance won’t just avoid fines—they’ll earn global trust and lead the next wave of AI.











Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now